
How to Build Scalable, End-to-end Batch Inference Pipelines with Daft
Daft makes it easy to express these pipelines end-to-end, while seamlessly scaling them up to handle massive workloads.
by Kevin WangThe landscape of LLM inference has grown quickly -- today, you have plenty of options. You can run inference with your own GPUs, or you can leverage inference providers like OpenAI and Anthropic. But when it comes to running inference at scale over large datasets, the problem isn't just "how do I run inference?"
Effective batch inference is much more than looping over your dataset and calling an LLM. A real-world batch inference pipeline often includes:
- Reading large volumes of data from a source (like Hugging Face, S3, or a database)
- Running inference efficiently across many prompts
- Writing the results back out, often in formats like Parquet or Arrow for downstream use
- Performing transformations and preprocessing steps in between
In other words: inference is usually just one piece of a bigger data pipeline.
In this post, we'll show you how Daft makes it easy to express these pipelines end-to-end, while seamlessly scaling them up to handle massive workloads.
Watch this on YouTube here.
Batch Inference Using OpenAI
Daft provides an llm_generate function that runs prompts through an LLM as part of your pipeline. Here's an example where we read a dataset of prompts from Hugging Face, run them through OpenAI's GPT-5, and write the outputs to Parquet:
import daft
from daft.functions import llm_generate
# Load dataset from Hugging Face
df = daft.read_csv("hf://datasets/fka/awesome-chatgpt-prompts/prompts.csv")
# Process through OpenAI API with automatic parallelization
df = df.with_column("output", llm_generate(
df["prompt"],
model="gpt-5",
provider="openai"
))
# Run the query and show a sample of the outputs
df.show()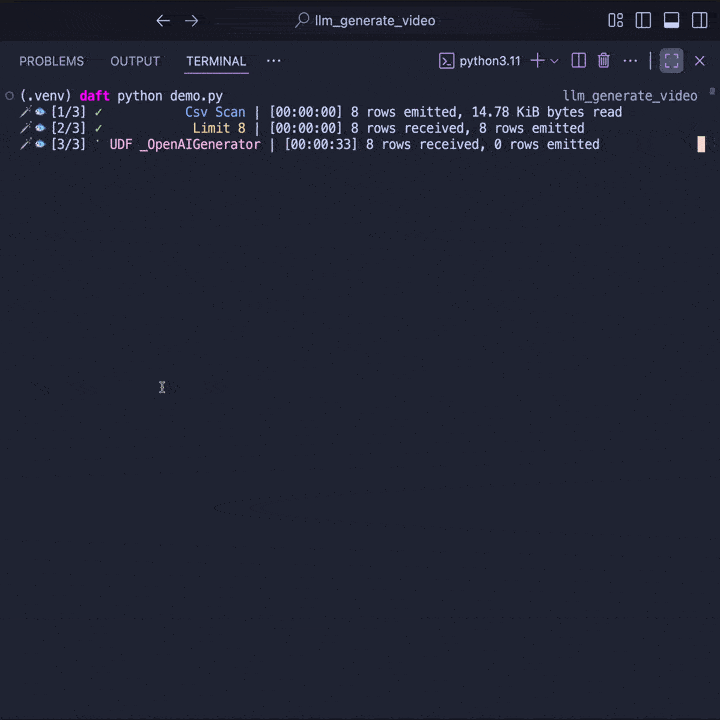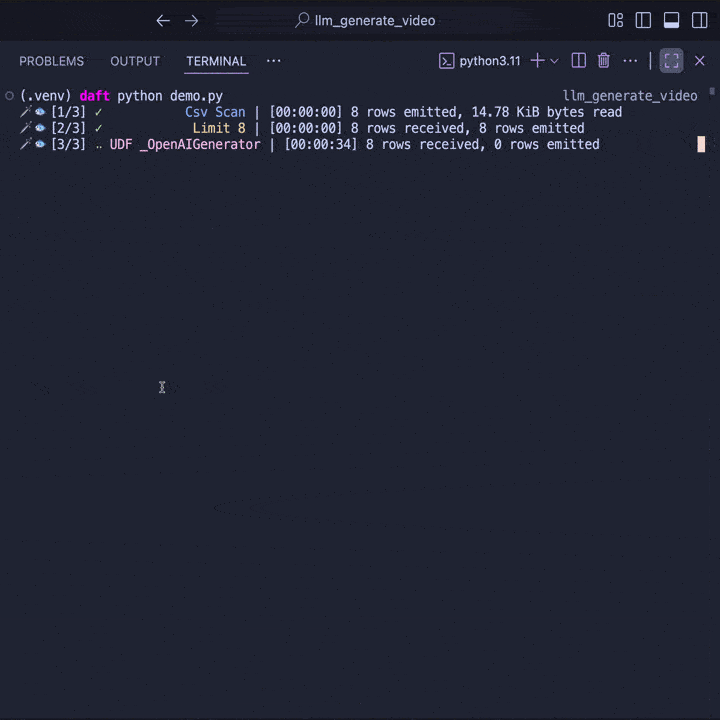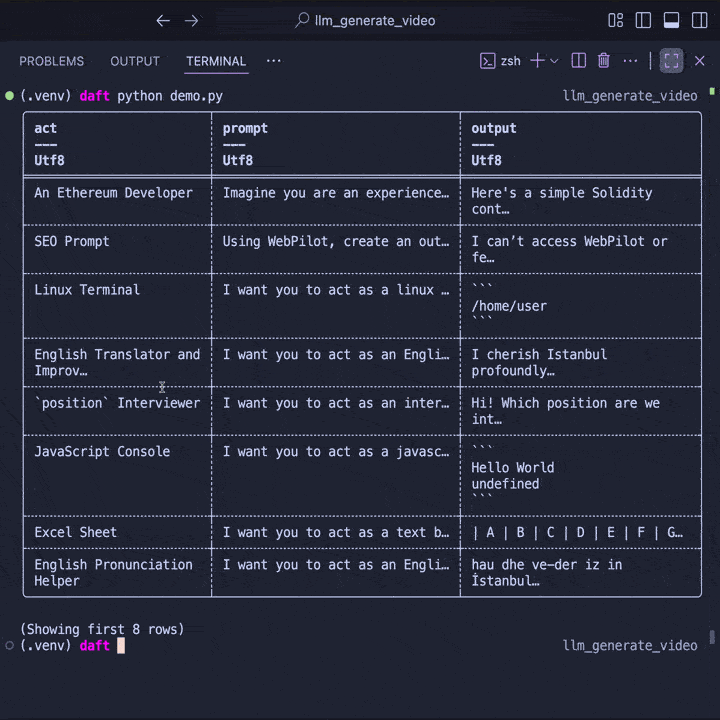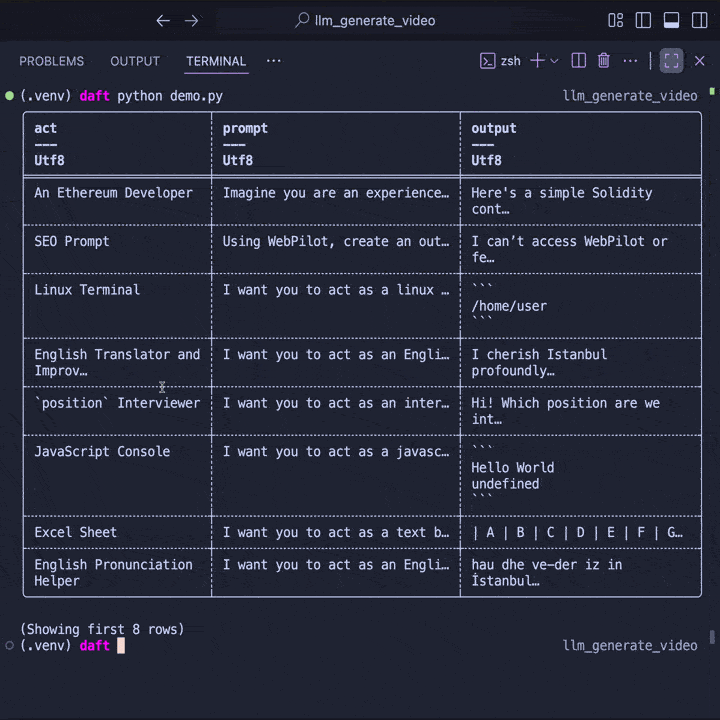
Behind the scenes, Daft automatically parallelizes requests to OpenAI to maximize throughput. Even better, Daft streams the data across stages -- reading, inference, and writing can all happen at the same time. This ensures your pipeline saturates network and CPU resources without you having to manage it manually.
Local Batch Inference Using vLLM
What if you'd rather run inference on your own GPUs? No problem. With Daft, you can switch providers by changing a single parameter. For example, here's how you'd run the same pipeline locally with vLLM:
# Switch to local vLLM inference
df = df.with_column("output", llm_generate(
df["prompt"],
model="Qwen/Qwen2-7B-Instruct",
provider="vllm"
))Daft integrates with vLLM, a high-throughput inference engine that batches and parallelizes calls under the hood. This makes it easy to get maximum performance out of your GPUs.
Tuning Local Inference
When running locally, you can further optimize throughput by tuning parameters:
concurrency-- the number of model instances to run (usually set to total GPUs / GPUs per model).batch_size-- the number of prompts sent to vLLM at once. Larger batch sizes improve throughput, but watch your GPU memory.
df = df.with_column("output", llm_generate(
df["prompt"],
model="Qwen/Qwen2-7B-Instruct",
provider="vllm",
concurrency=4, # Number of concurrent model instances
batch_size=32 # Prompts per batch
))Scaling Out
As your workloads grow, you'll eventually hit scaling limits. That could be because:
- Your dataset no longer fits on one machine
- You don't have enough compute to finish in time
- Network throughput becomes a bottleneck
Traditionally, scaling out means rewriting your pipeline with distributed systems in mind -- partitioning data, scheduling work, coordinating results. That's a lot of complexity.
With Daft, scaling is simple. All the code above works in distributed mode with a single additional line:
daft.context.set_runner_ray()Now, by running your script on a Ray cluster, Daft automatically handles partitioning, scheduling, and coordination for you. Your workload seamlessly leverages all available CPUs, GPUs, and networking across the cluster. No pipeline rewrites needed.
Learn more in our distributed execution docs.
Conclusion
Daft makes it easy to build scalable, end-to-end batch inference pipelines.
- The
llm_generatefunction lets you write provider-agnostic pipelines that work with both inference APIs and your own GPUs. - Switching between OpenAI and local vLLM is just a parameter change.
- Scaling out to a cluster is a single-line addition.
If you're looking for a way to take batch inference beyond "for loops" and into a production-ready pipeline, Daft provides the tools to do it -- efficiently and simply.
Try it out yourself pip install daft and check out our documentation.

