
Making GPUs Zoom (Part 1)
How Daft is approaching large-scale model inference with advanced GPU optimizations for faster multimodal AI workloads
by Srinivas LadeA deep dive into GPU optimizations for production-scale multimodal data processing
Multimodal data processing at scale hits a performance wall with models. You read metadata from S3, easily download thousands of files in parallel, and preprocess them across dozens of cores, only to watch everything grind to a halt at model inference. The result? Your high-performance, pricey GPU sits mostly idle.
At Eventual, we're making Daft, the library for running models on data. That means, aside from being easy-to-use and reliable, it has to squeeze out every drop from the available hardware. In this article, I will explore how models execute on GPUs and share some of the various optimizations we're rolling out into Daft.
The Reality of Modern AI Architectures
Unfortunately, there is no one-stop solution to making AI models faster. Many of the cutting-edge models are messy by design:
- They consume diverse inputs and produce equally varied outputs
- Internally, they can run arbitrary code on across different hardware (CPU, GPU, etc)
- Some may already be tuned for specific use-cases, like model serving
On top of that, many optimizations depend on the workload and data involved. Different bottlenecks appear when feeding text into a LLM vs. images and video processing.
However, there are a class of well-established, highly optimized models to solve common problems across multiple use-cases. These models are often purpose-built for GPUs. So we asked ourselves: what if we stopped treating these models as black boxes, and instead started unraveling their internals?
Disclaimer
Note that throughout this blog post, we'll be mainly referring to documentation about NVIDIA GPUs and CUDA's programming model. While many of the concepts map to other GPU architectures like AMD ROCm (via HIP) or Apple silicon GPUs (via the Metal Performance Shaders framework, aka mps), we focused on CUDA because of the available documentation.
What's an example of an interesting query?
One workload we've started looking into is image embedding generation. We can break it down into the 4 general steps:
- Load the data from storage (S3, HTTP, etc)
- Pre-process it
- Generating embeddings (either with an API or local model, like in our case)
- Save the embeddings (either to a vector DB or local files)
Implementing this kind of pipeline only requires ~10 LOC in Daft v0.6.1 (or 1 if you really wanted to).
import daft
from daft import col
from daft.functions import embed_image
(
daft
.read_huggingface("laion/conceptual-captions-12m-webdataset") # Load
.limit(5000)
.with_column("image", col("jpg")["bytes"].image.decode())
.with_column("embedding", embed_image(col("image"))) # Pre-process and embed
.select("__key__", "embedding").write_parquet("embeddings.pq") # Write
)But for the purposes of this conversation, let's unravel the APIs to show what's running behind the scenes. For our example, let's use the torchvisions library and ResNet50 for the embedding model.
import daft
from daft import col, DataType
import numpy as np
import torch
import time
from torchvision import transforms
from torchvision.models import resnet50, ResNet50_Weights
transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
@daft.udf(
return_dtype=DataType.tensor(dtype=DataType.float32(), shape=(3, 224, 224)),
batch_size=8,
)
def pre_process(images):
return [transform(image) for image in images]
@daft.udf(
return_dtype=daft.DataType.list(dtype=daft.DataType.float32()),
batch_size=32,
concurrency=1,
num_gpus=1
)
class ResNetModel:
def __init__(self):
weights = ResNet50_Weights.DEFAULT
self.model = resnet50(weights=weights)
self.model = self.model.eval()
self.model = self.model.cuda()
def __call__(self, images):
if len(images) == 0:
return []
input_tensor = torch.as_tensor(np.array(images.to_pylist())).cuda()
with torch.inference_mode():
result = self.model(input_tensor)
converted_result = result.cpu().numpy()
return converted_result
(
daft
.read_huggingface("laion/conceptual-captions-12m-webdataset") # Load
.limit(5000)
.with_column("image", col("jpg")["bytes"].image.decode())
.with_column("proc_image", pre_process(col("image"))) # Pre-process
.with_column("embedding", ResNetModel(col("proc_image"))) # Embed
.select("__key__", "embedding").write_parquet("embeddings.pq") # Write
)Let's run this on a g5.2xlarge using the Ubuntu 22.04 Deep Learning PyTorch AMI with environment variable DAFT_DEV_ENABLE_EXPLAIN_ANALYZE=1 set for a breakdown over time. Plotting the results, 3 steps dominate.

There are optimizations we can perform on the model itself to make it faster, such as JIT compilation, using F16 precision, or just using a smaller variant of ResNet. But let's put those aside and ask: what can we do in Daft to make inference faster?
Insight (1): GPUs are effectively remote machines
Under the hood, the Daft engine is an asynchronous runtime that's capable of working on both IO-heavy tasks and CPU computations in parallel. It achieves this by coordinating 2 dedicated runtimes: a CPU runtime for blocking code and an IO runtime for remote calls.
Most multimodal pipelines evenly divide work between IO and compute. Thus our multi-runtime approach is able to effectively overlap tasks; coupled with our record-setting I/O backend, we can maximize hardware utilization & pipeline parallelism while minimizing the overall runtime.
For example, consider a pipeline that generates image thumbnails:
import daft
(
daft.read_huggingface("laion/conceptual-captions-12m-webdataset")
.with_column("image", col("jpg")["bytes"].image.decode())
.with_column("thumbnail", col("image").image.resize(1280, 720).image.encode())
.select("__key__", "thumbnail").write_parquet("thumbnails.pq")
)If we look at an execution timeline for this query on a 1-core machine, it would look something like this:
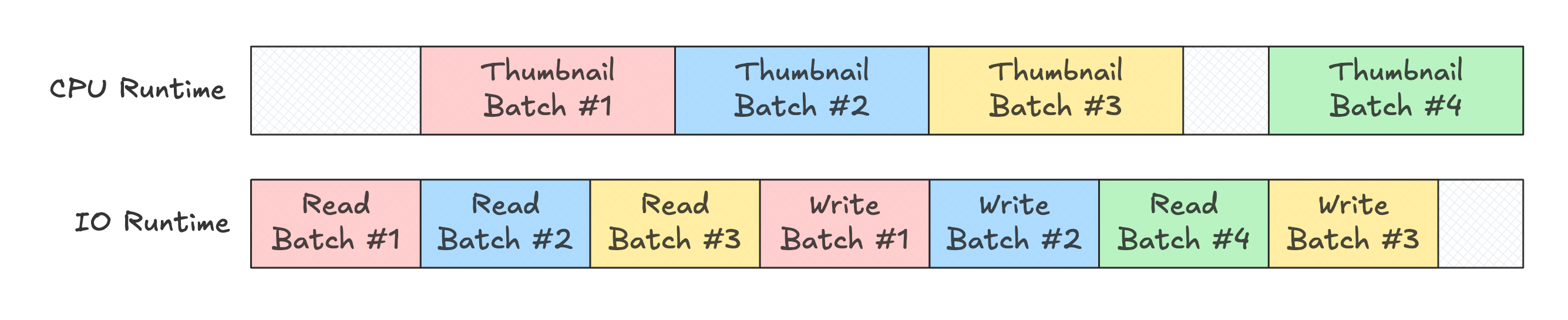
This is exactly what we want; as we generate thumbnails for one batch of images, we are uploading previously finished batches and downloading new ones. We can nearly keep the entire system busy with something to do.
What about our image embedding workflow?
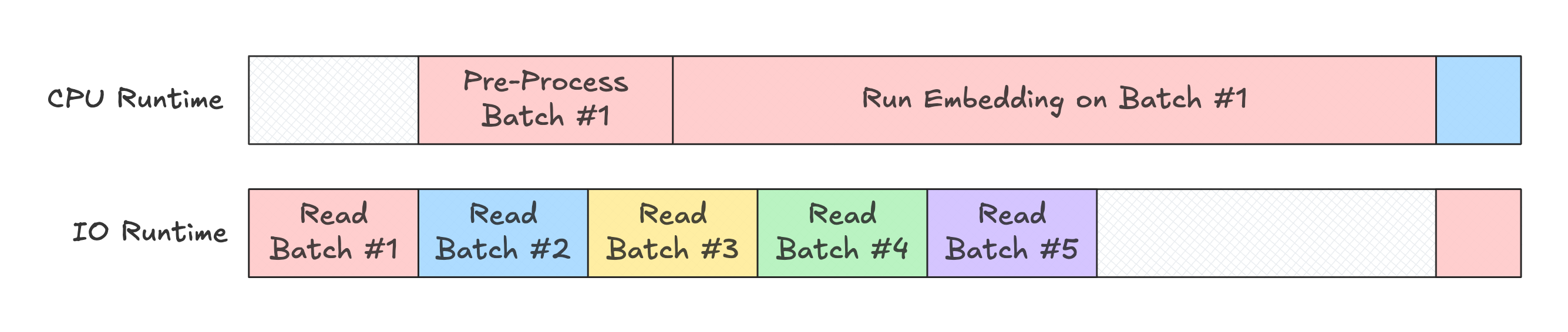
So by tripling the amount of computation with the embedding model, we end up "blocking" the other 3 steps. The CPU runtime doesn't have the bandwidth to pre-process the next batch, and IO is just waiting to write out batch #1 before it loads batch #6. What exactly can we do to make it faster without making embedding generation itself faster?
What does it mean to run a model?
For the models we're trying to optimize for, running inference on a model means running a single or multiple consecutive "GPU functions", aka CUDA kernels. How do they get triggered?
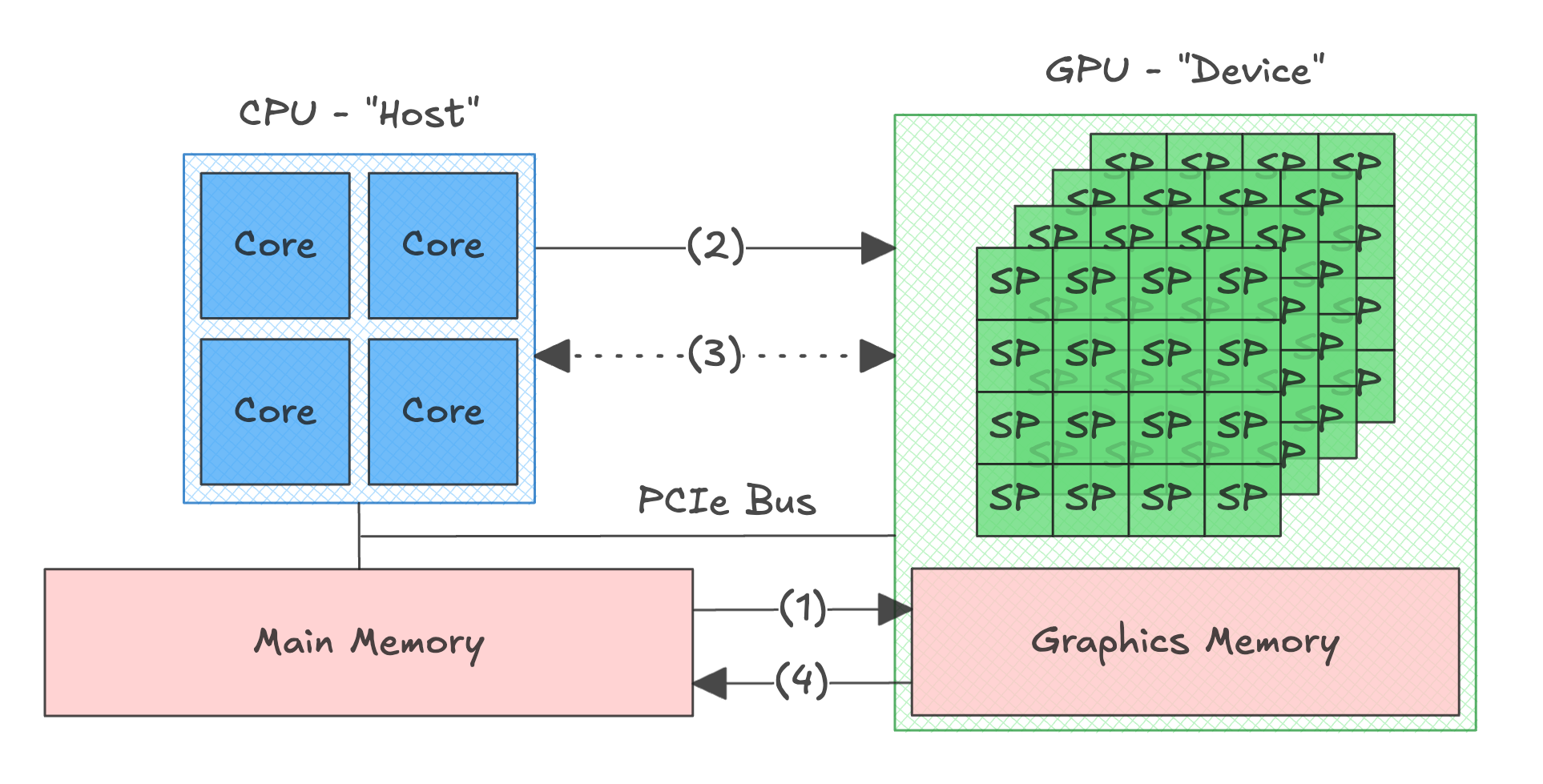
Our program, running on the CPU, would perform 4 steps to trigger a CUDA kernel
- First, we transfer our input tensor from main memory to the GPU's internal memory, often called graphics memory or VRAM
- We trigger the start of a CUDA kernel
- We "wait" for the CUDA kernel to complete
- We transfer the resulting tensor back to main memory
For a significant amount of time, our program is just busy-waiting by polling the kernel for completion so it can get back the result. That seems like kind of a waste, particularly because we could have spent that time reading and pre-processing the next batch. It turns out that this is possible with the torch.cuda API, using CUDA events.
# Before
input_tensor = torch.as_tensor(np.array(images.to_pylist())).cuda()
with torch.inference_mode():
result = self.model(input_tensor)
converted_result = result.cpu().numpy()
# After
start_event = torch.cuda.Event()
end_event = torch.cuda.Event()
input_tensor = torch.as_tensor(np.array(images.to_pylist()))
start_event.record()
cuda_input = input_tensor.cuda(non_blocking=True)
with torch.inference_mode():
result = self.model(input_tensor)
end_event.record()
while not end_event.query():
# Do something else
converted_result = result.cpu().numpy()If we scope the GPU-specific code between two CUDA events, we can poll the end_event to see if the operations have completed. While they are still running, we can go work on something else.
What would this look like in Daft?
So what if we treated GPU kernels like any other async function? Well, then our throughput diagram would look something like this (horizontally compressed):
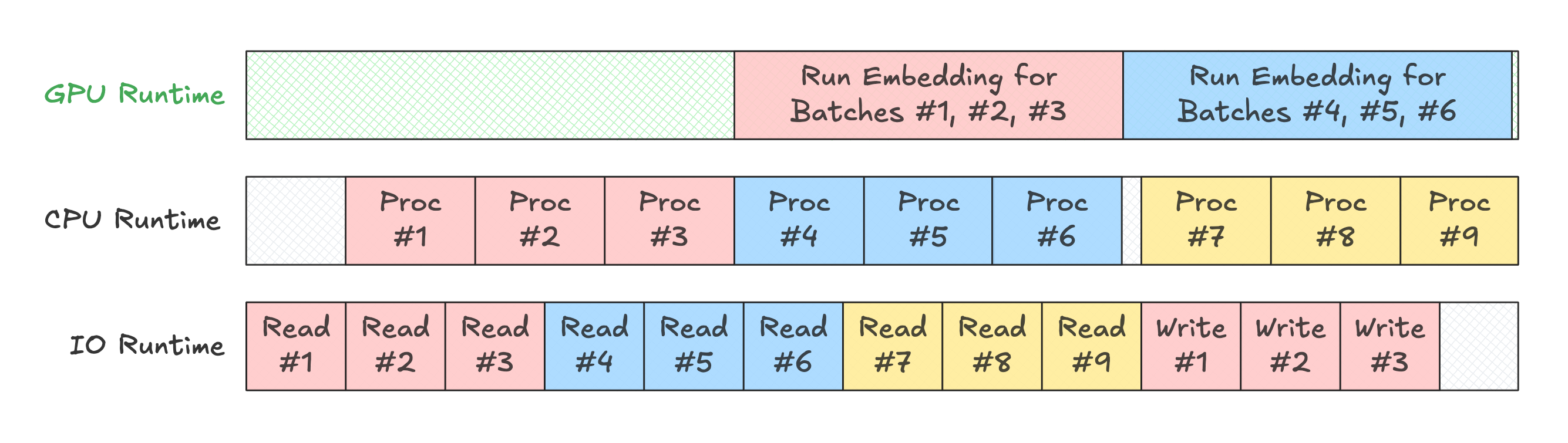
That's much better! Instead of having our CPU runtime block on embedding generation, we can pre-process the next 3 batches of images and prepare them for the next kernel invocation.
Broadly speaking, Daft should treat GPU kernels like Daft treats other external resources—as an async operation. Just as Daft doesn't block while reading from S3, it shouldn't block for the output from a model.
Insight (2): Concurrent GPU Kernels with CUDA Streams
Most of the time, we use Daft in a multi-core environment, where multiple threads execute concurrently. Let's tweak our ResNet UDF to take advantage of this, by setting the parameters concurrency=3 and num_gpus=0.3. What should the timeline look like for our embedding workflow then?
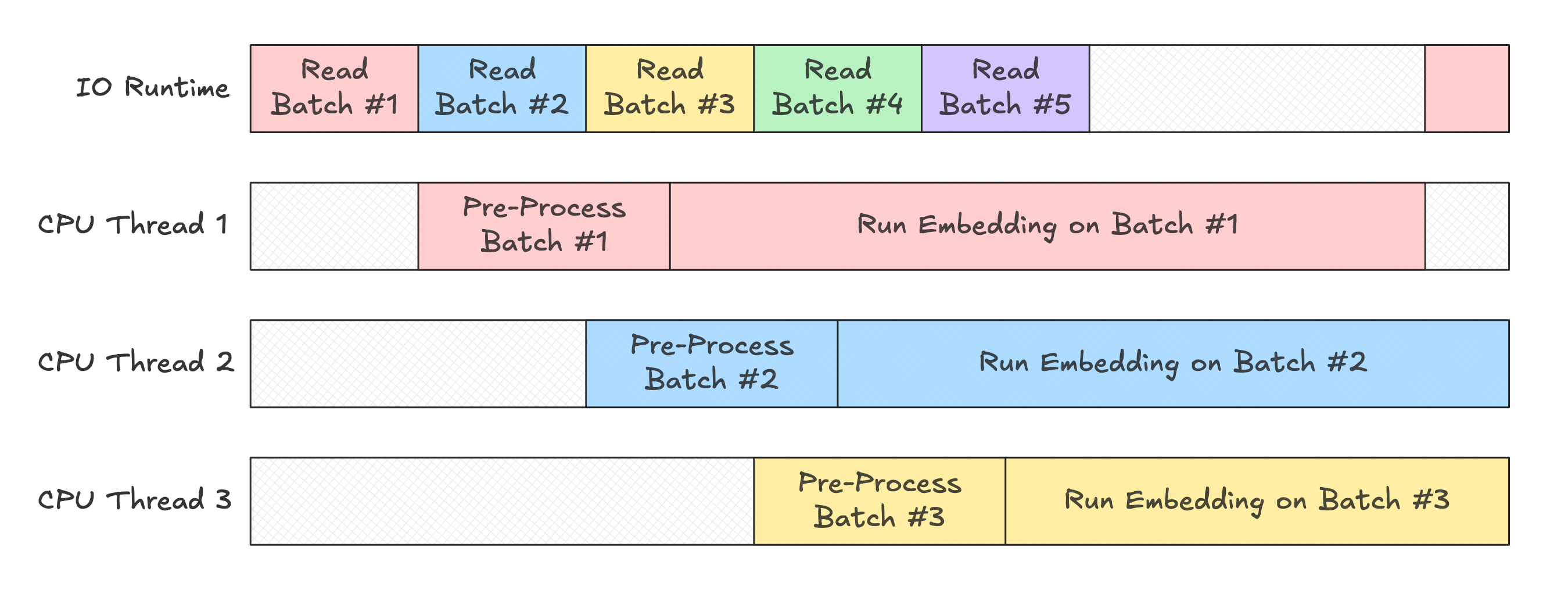
What does it end up looking like in practice?
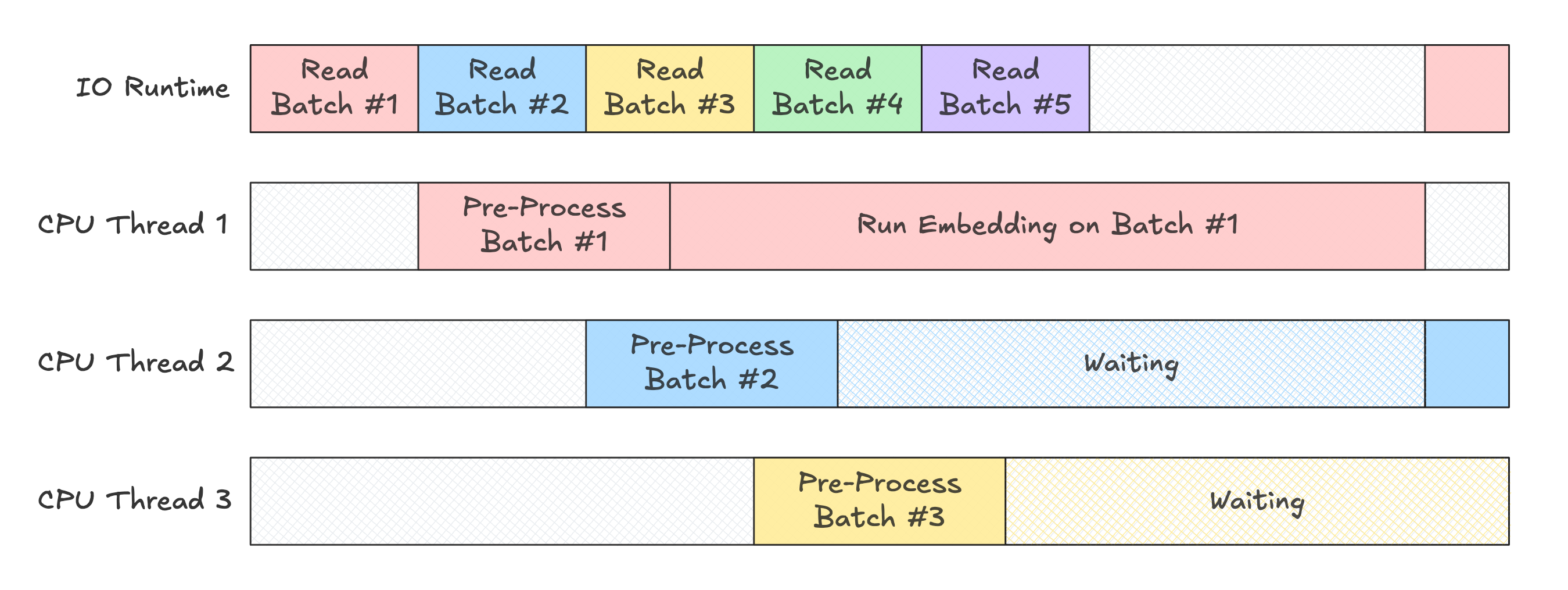
Hmm, so even though we can generate embeddings for multiple batches, we are only doing so one at a time. Why is that?
CUDA Streams
When we execute the model, the underlying CUDA kernels are placed on a "queue" on the GPU, such that the operations are performed in a first-in-first-out manner. This "queue" is called a CUDA stream. CUDA makes the assumption that operations in the stream are in order of dependencies; it's not possible to start the second operation while the first is running.
By default, every process is assigned a single stream, so every subsequent model call ends up waiting for the previous to finish. That's why we don't see any overlap!
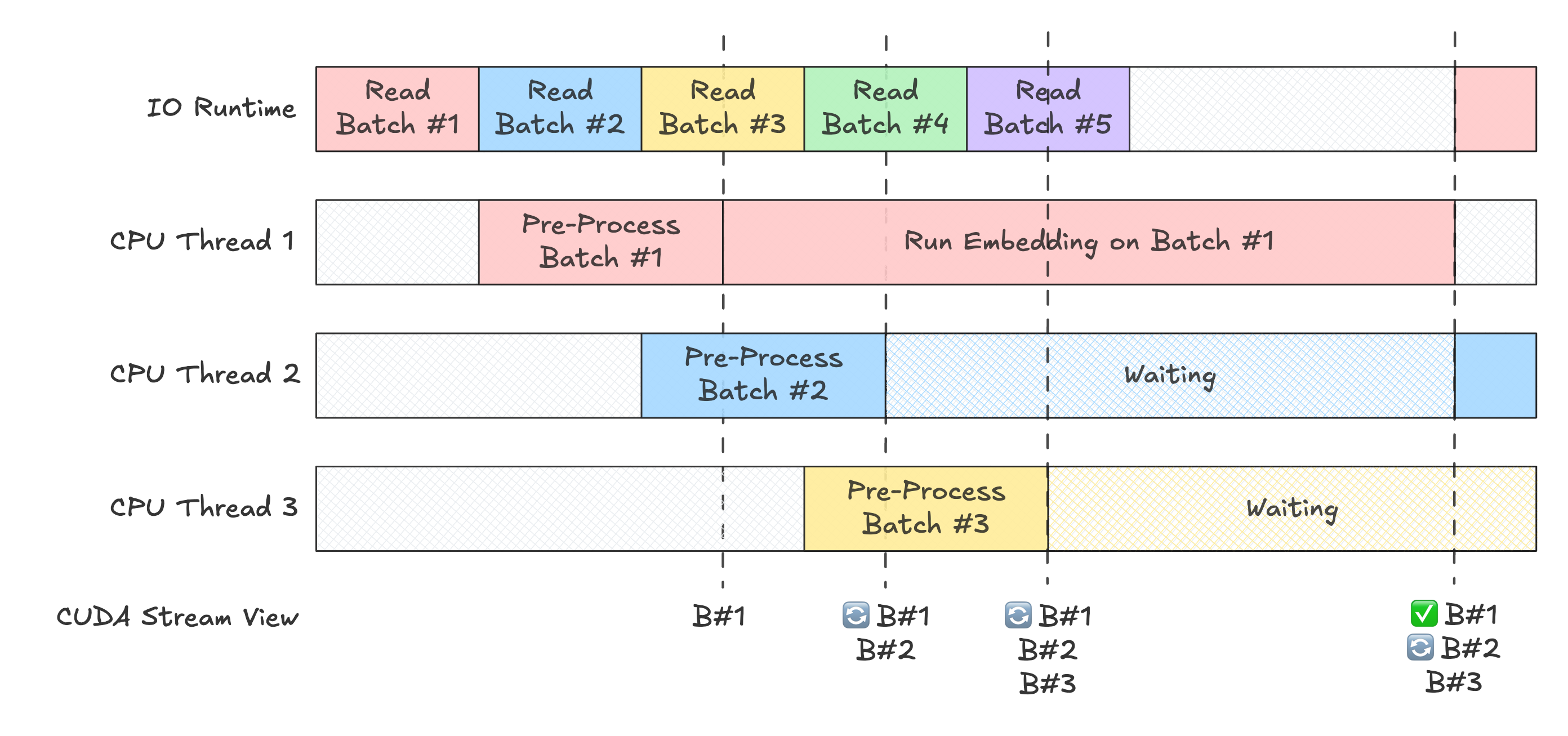
How can we work around this? Thankfully, PyTorch provides the very convenient torch.cuda.Stream API to isolate model inference calls to independent streams that can run concurrently.
# Before
...
with torch.inference_mode():
result = self.model(input_tensor)
...
# After
with torch.cuda.stream(torch.cuda.Stream()):
...
with torch.inference_mode():
result = self.model(input_tensor)
...By using separate streams, we can schedule multiple embedding runs and inform the GPU driver that each run is independent of the other. Thus, the driver can potentially work on multiple at the same time.
Same as before, but now we can start multiple runs in parallel and poll all together.
Ideally, we should reuse streams since creating a new one leads to some overhead, but that's a smaller improvement.
Whether the GPU will actually start execution 2 kernels at the same time is dependent on the architecture of the GPU and its compute capabilities. If it has the available cores that are independent, or it sees similar operations across 2 runs, it may. We will explore more about GPU scheduling the part (2) of this series.
Great! How can I try this?
With just one step: pip install daft! Our goal is to offer a simple API to work with popular model libraries and common multimodal operations. Behind the scenes, Daft uses the optimal algorithms to take full advantage of the underlying hardware so you don't have to.
We're just getting started with GPU optimizations in Daft, and there's plenty more to come. If you'd like to follow along, give us a star on GitHub and follow us on LinkedIn. Stay tuned for part 2 on our blog, where we will delve into automated GPU memory management. See you soon!
References:

