
Cutting LLM Batch Inference Time in Half: Dynamic Prefix Bucketing at Scale
Learn how Dynamic Prefix Bucketing reduces LLM batch inference time, improves throughput, and unlocks faster multimodal processing at scale.
by Kevin WangA new inference backend that maximizes batch inference throughput.
TL;DR
At Daft, we are committed to building the best tools for running models on your data. We know that LLM batch inference is often difficult, costly, and slow, but we believe it doesn't have to be that way. Today, we are releasing an inference backend in beta that cuts batch inference time in half.
This new vLLM Prefix Caching provider is able to accomplish this by combining the power of the vLLM serving engine with Daft's distributed execution Flotilla to do two things:
- Dynamic Prefix Bucketing - improving LLM cache usage by bucketing and routing by prompt prefix.
- Streaming-Based Continuous Batching - Pipeline data processing with LLM inference to fully utilize GPUs.
Combined, these two strategies yield significant performance improvements and cost savings that scale to massive workloads. We observe that on a cluster of 128 GPUs (Nvidia L4), we are able to complete an inference workload of 200k prompts totaling 128 million tokens up to 50.7% faster.
You can try it out today on Daft v0.6.9 by setting your provider to "vllm-prefix-caching" on our prompt AI function. Here's a quick example:
from daft.functions import prompt
df = daft.from_pydict({
"input": ["How many r's are in strawberry?"]
})
df = df.with_column("output",
prompt(
df["input"],
provider="vllm-prefix-caching",
model="Qwen/Qwen-8B"
)
)
df.show()AI Functions in Daft
Daft provides a suite of native AI functions that allow you to run embedding, classification, and generation tasks over your data with just a few lines of code.
Here's a quick example using OpenAI's text-embedding-3-small to compute embeddings over a column of data:
>>> import daft
>>> from daft.functions import embed_text
>>>
>>> df = daft.from_pydict({"text": ["Hello World"]})
>>>
>>> df = df.with_column(
... "embeddings",
... embed_text(
... df["text"],
... provider="openai",
... model="text-embedding-3-small"
... )
... )
>>>
>>> df.show()
╭────────┬──────────────────╮
│ text ┆ embeddings │
│ --- ┆ --- │
│ String ┆ Embedding[Float32; 1536] │
│════════╪══════════════════╡
│ Hello World ┆ ▆█▆▆▆▃▆▆▂▄▃▂▃▃▄▁▃▅▂▃▂▂▂▂ │
╰────────┴──────────────────╯More than just being convenient, these AI functions provide a consistent abstraction layer between the usage of a model and the underlying execution of the model. Without changing the AI function call itself, you can modify the way it is executed by changing the model provider.
For instance, if you wanted to run a local embedding model in the above script instead of calling OpenAI, simply update the provider and model:
embed_text(
df["text"],
provider="transformers",
model="sentence-transformers/all-MiniLM-L6-v2"
)We leverage this abstraction to build a "vLLM Prefix Caching" provider, which is able to significantly improve the performance of the prompt function by simply changing the selected provider, just like you saw above.
The rest of the blog post details the design and implementation of this new provider within Daft, and the performance results we saw with these changes.
Introduction to LLM Batch Inference
LLM inference workloads fall into two distinct camps with fundamentally different optimization targets.
Online inference serves real-time requests: ChatGPT conversations, IDE code suggestions, agentic workflows. The model sits directly in the user loop. What matters: Time-to-first-token and individual completion tokens per second.
Batch inference pre-processes entire datasets offline: computing embeddings for vector DBs, labeling datasets for analysis, generating synthetic training data. No user waiting on the other end. What matters: tokens per dollar and aggregate tokens/second.
Batch inference presents several unique challenges and opportunities over online inference:
| Online Inference | Batch Inference | |
|---|---|---|
| Performance | Latency of individual requests is critical. (TTFT, Tokens/sec) | Overall throughput of the inference pipeline is the main concern. (Tokens/$) |
| Size of data | Typically handles one or few inputs at a time, so memory limits are rarely an issue. | The entire dataset may not fit into CPU or GPU memory. |
| Cost and GPU utilization | Costs depend on per request or per token usage; GPUs may be underutilized between requests. | Costs are tied to GPU hours; effective utilization across the batch is essential for efficiency. |
| Data distribution | Prompts arrive in real time, so data distribution is unknown ahead of time. | All prompts are known in advance, allowing optimizations that leverage data distribution. |
Streaming-Based Continuous Batching
A simple and scalable method of doing batch inference is as follows:
- Spin up N replicas of an LLM serving engine across a compute cluster such that all GPUs are occupied.
- Split your dataset into batches that are small enough to fit into memory.
- Distribute those batches evenly across the replicas.
- Run inference on one batch at a time.
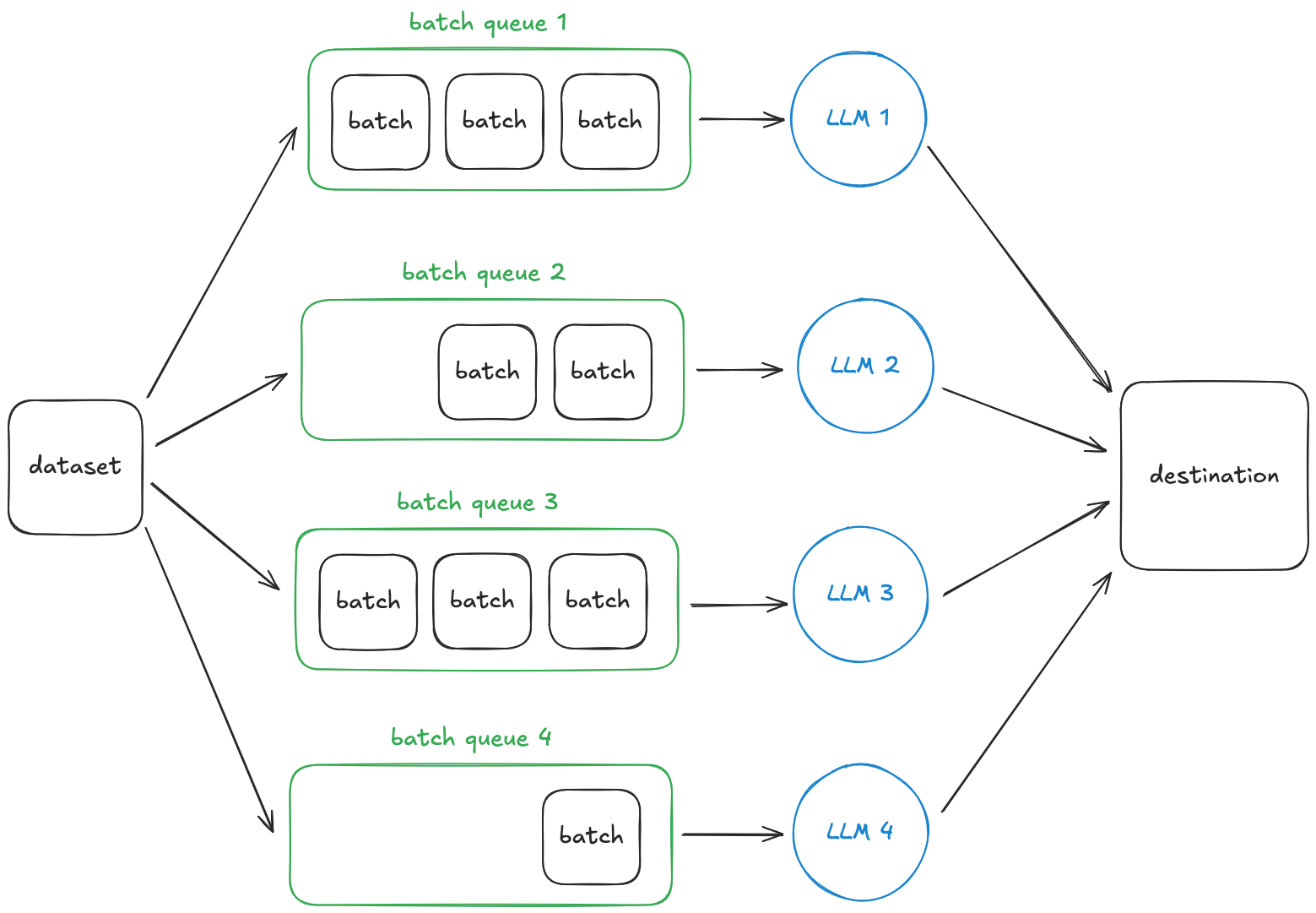
However, you'll observe two things:
- The GPU is idle between the end of one batch and the start of the next. This is because there are a series of pre-inference and post-inference steps, including tokenization, data transfers, and batching, all of which will be done while the GPU sits idle.
- Within a batch, some requests complete before others, leading to a lagging tail of longer sequences where the GPU isn't fully utilized. Since LLM inputs and outputs have variable length, some sequences require more generation steps than others.
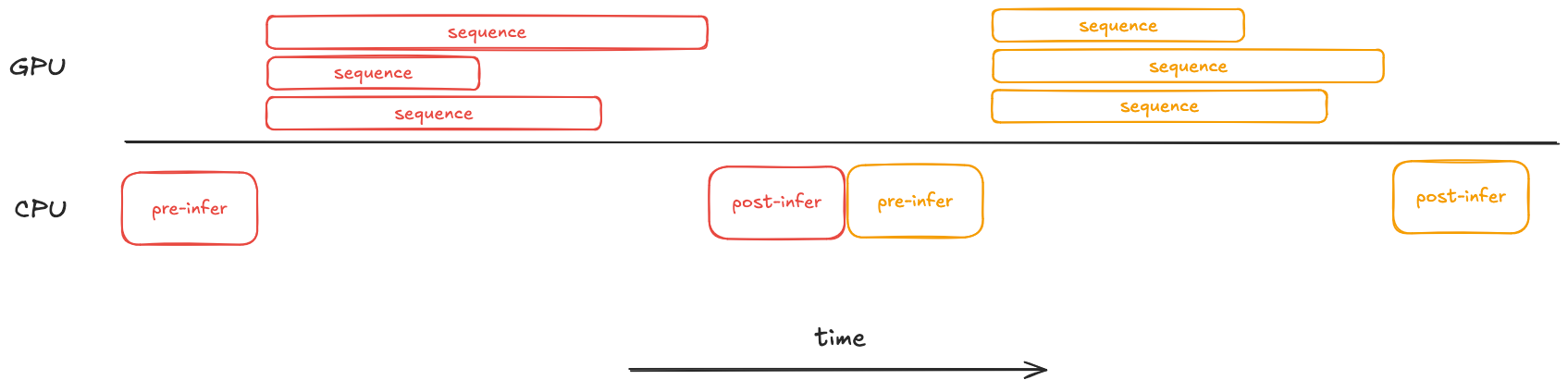
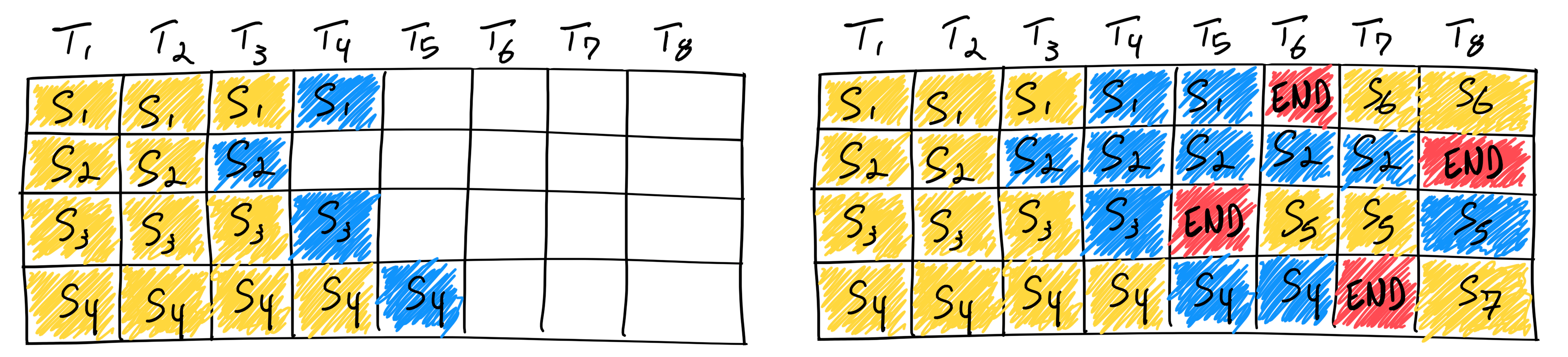
To solve this, we can leverage a technique in vLLM called continuous batching. The fundamental improvement of continuous batching is that we're able to now batch inference on a per token basis instead of per sequence. This allows us to start inference on prompts in the next batch as sequences in a previous batch complete. There is an excellent blog post about continuous batching if you'd like to learn more about how this works.
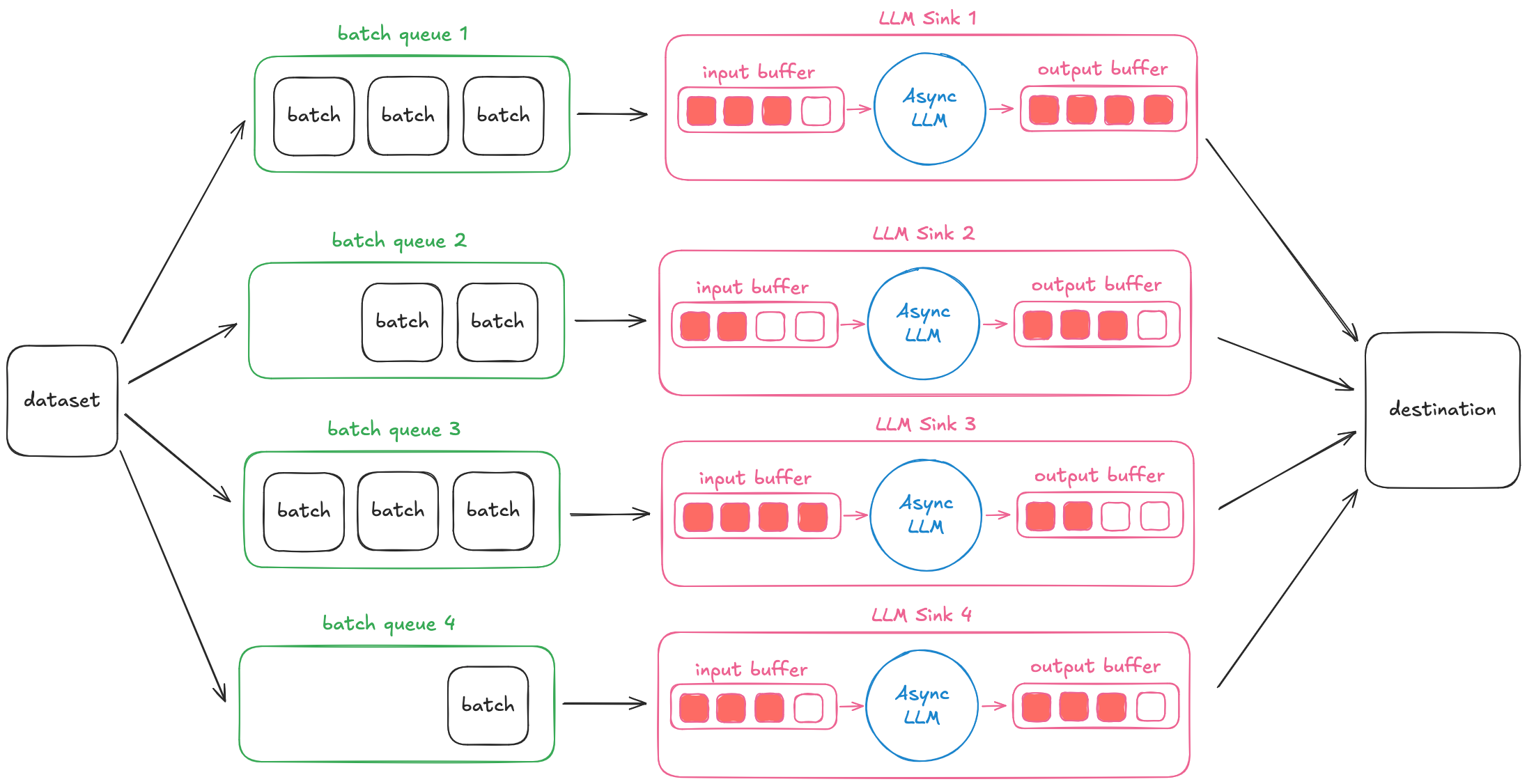
To implement continuous batching across an entire dataset, we leverage Daft's streaming execution capabilities to implement a "streaming sink", a class of operators that are able to stream batches in and out while accumulating state across batches.
Tip - Learn more about streaming execution in our blog about Swordfish, our local execution engine!
In this LLM operator, we collect input batches into a buffer that is fed into vLLM using the AsyncLLMEngine API. This ensures that there is always more data for a serving engine to add to the batch. The serving engine pushes completed sequences into an output buffer, which gets streamed out into later pipeline stages.
Dynamic Prefix Bucketing
Model prompts often contain repetitive content, like system prompts and common instructions. In those cases, we can leverage prompt caching to avoid recomputing common prefixes. In vLLM, this is called automatic prefix caching. When enabled, vLLM attempts to cache the computed values of a sequence across requests and store it in GPU memory (VRAM).
This means that if you have inputs with common prefixes, a significant amount of the computation can be avoided as long as the previous cached result is still in GPU memory.
In batch inference workloads, the challenge with effectively using the prefix cache is twofold:
- Cache Eviction - GPU VRAM is a limited resource, so a prefix cache block may be quickly evicted. If you have two sequences with a common prefix, but their requests are spaced far apart, prefix caching will not take effect.
- Cache Locality - The prefix cache is local to an individual serving engine. In a cluster with multiple replicas, if two requests with the same prefix are served by different replicas, we are unable to reap the benefits of prefix caching either.
One straightforward method to improve the cache hit rate is to do a distributed sort prior to inference. That way, inputs with common prefixes are grouped together on the same machine.
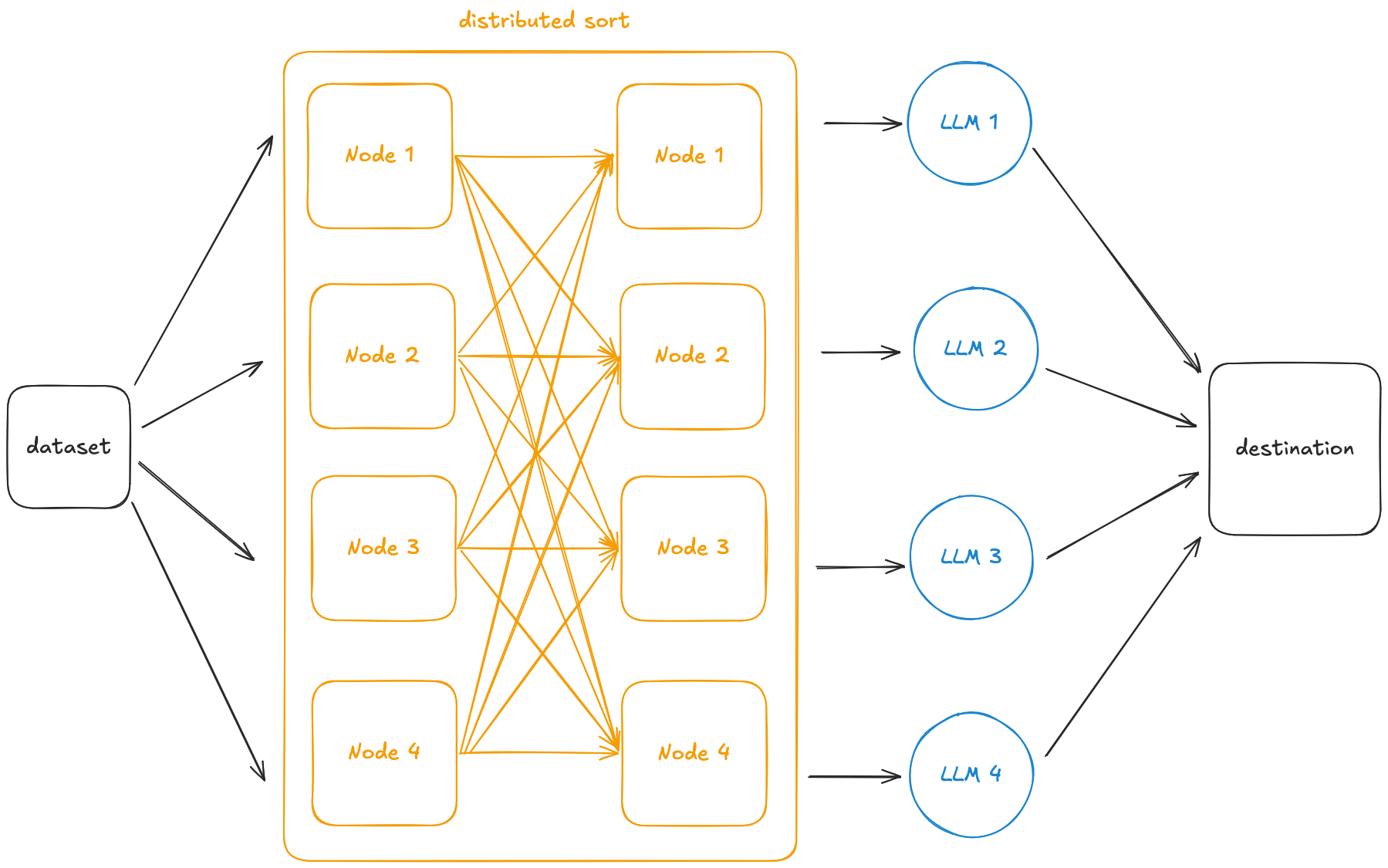
However, sorting is a blocking operation, meaning GPUs are sitting idle until it completes. It also requires full materialization of your dataset, which may not be possible for large-scale data.
Instead, we developed "dynamic prefix bucketing", a method that simultaneously improves prefix cache hits while achieving high GPU utilization throughout an entire query. Dynamic prefix bucketing consists of two components: local prefix bucketing and prefix-aware routing.
Local Prefix Bucketing
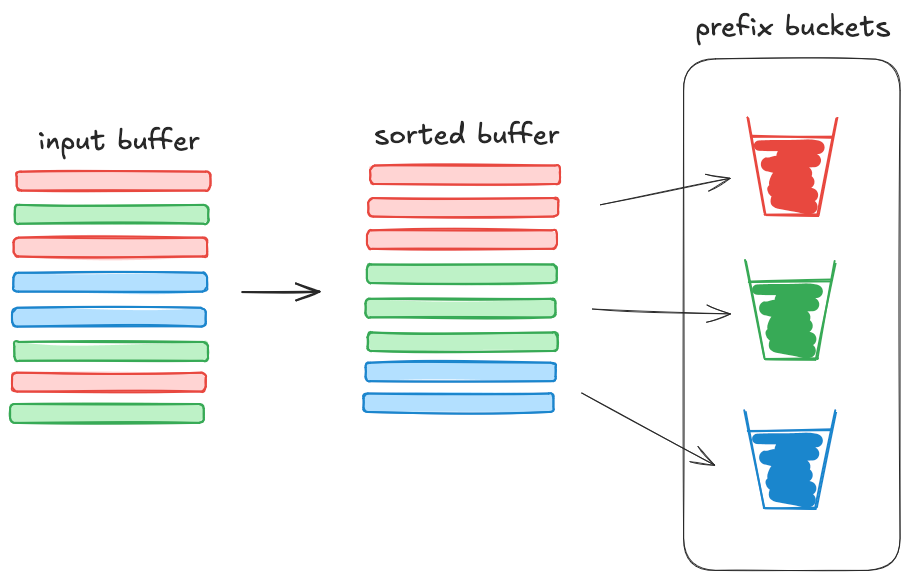
On each local machine, we maintain a buffer of inputs, bucketed by prefix. To pop from the buffer, we remove input buckets by size, largest bucket first. Insertions and removals are interleaved, meaning small buckets are kept until they are able to grow large enough to submit.
Buckets are computed dynamically by first sorting the buffer, then determining bucket boundaries by checking the common prefix length of adjacent prompts. If the common prefix is under a certain threshold (e.g. 30% of each prompt), start a new bucket. Otherwise, add the next prompt into the current bucket.
Prefix-Aware Routing
To determine the replica to send a batch to, local executors query a global LLM router. The router determines the best replica to route to, factoring in both prefix cache locality and load balancing. Out of the replicas that have the lowest load (determined by a threshold value), the router selects the replica that has most recently seen the given prefix to send a batch to.
This router ensures that all replicas are sufficiently utilized, while allowing prefix caching over data from separate machines. It is also effective against data skew, because if there are some prefixes that are very common across the dataset, it will avoid routing all prompts with such a prefix to a single serving engine.
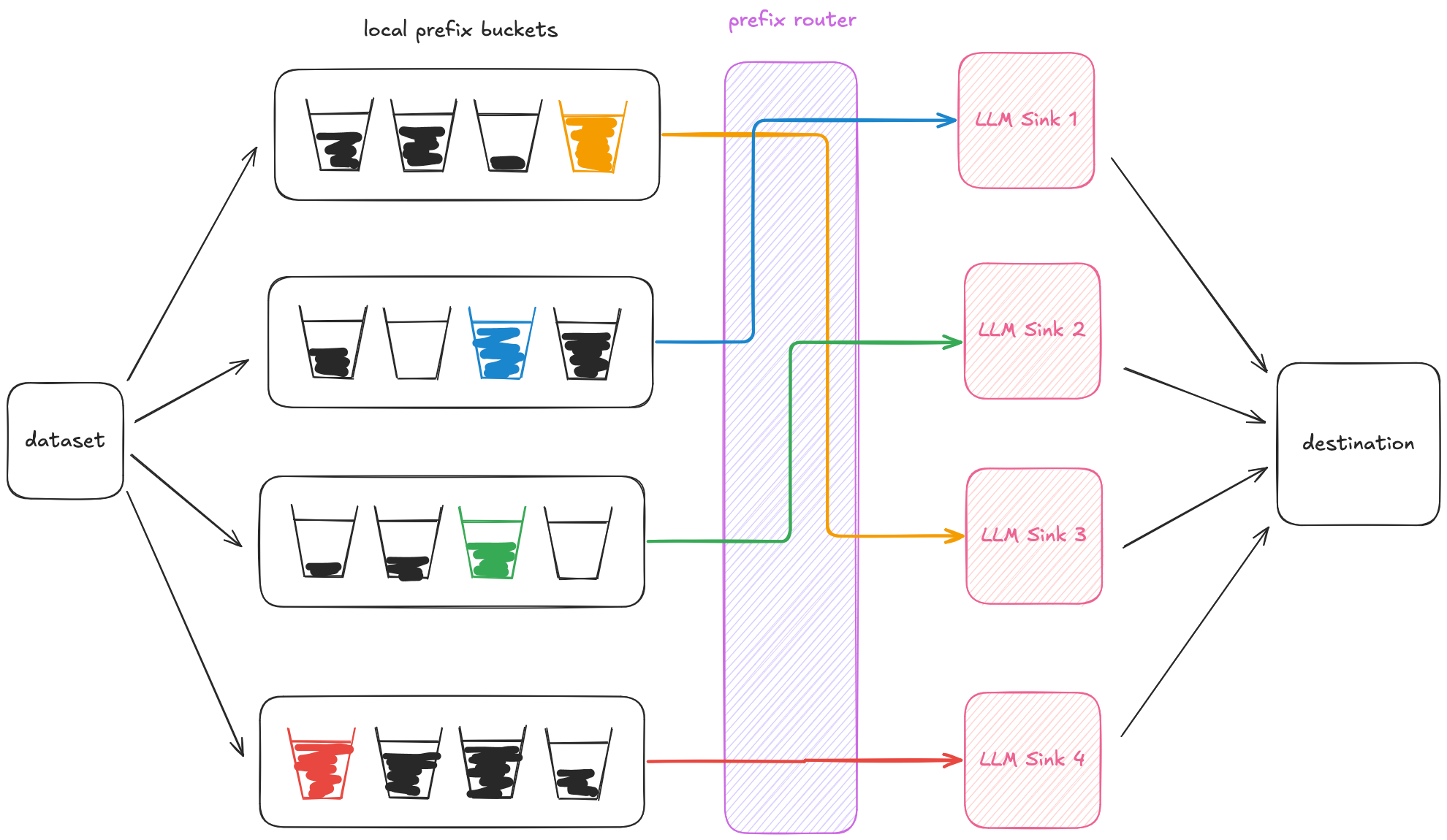
By combining local bucketing and global routing, we are able to improve cache hits across the cluster, all the while streaming data through. This method makes use of GPUs almost instantly once data is available and does not require full dataset materialization. As a result, even if your dataset is too large to fit into memory, dynamic prefix bucketing is still able to run batch inference over it with high performance.
Benchmarking Setup
All benchmarking and dataset generation scripts can be found in the Daft repository on Github.
Dataset
To evaluate our system and for benchmarking, we used vLLM's PrefixRepetitionRandomDataset to generate a 102 million token dataset with 200k prompts with 512 tokens for each prompt, with 512 unique prefixes of 256 tokens (half the prompt).
Workload
We chose the Qwen/Qwen3-8B model in bfloat16 precision, a popular model used in batch inference for tasks such as synthetic data generation, product enrichment, and structured extraction.
For each input prompt, we generated 128 output tokens and used a temperature of 1. This generates around 25.6M output tokens.
Hardware
For our hardware, we use NVIDIA L4 GPUs which have 24gb of memory and can comfortably host Qwen3-8B in bfloat16 with room for the KV Cache.
Our pick for servers were g6.12xlarge which each had 4 L4 GPUs, 48 CPU cores, 192GB of DRAM and 40 Gbps network.
We ran our setup in 3 configurations to test the scalability of our methods.
| Config | Number of GPUs | CPU cores | Network (Gbps) |
|---|---|---|---|
| 8 x g6.12xlarge | 32 | 384 | 320 |
| 16 x g6.12xlarge | 64 | 768 | 640 |
| 32 x g6.12xlarge | 128 | 1536 | 1280 |
Benchmark Results
Methods
Naive Batching (Baseline)
Our baseline method consists of simply splitting the input data into batches of 512 prompts and sending them into the serving engines sequentially. We implemented this via Daft's class-based batch UDFs.
Naive Batching on our 128 GPU configuration takes 977 seconds and has a 29.2% Cache Hit Rate.
Our next step is to try continuous batching that could potentially improve pipelining and combat the issue of stragglers.
Continuous Batching
With continuous batching, we instead maintain a buffer of tasks for each serving engine to process, implemented as a pool of async tasks that call AsyncLLMEngine.generate on vLLM. The serving engine pops prompts from the task pool in order to maintain a consistent batch of sequences to run inference over.
Continuous batching takes 869 seconds and yields a 11% speedup. We also see that the cache hit rate decreases from 29.2% to 26.5%. We believe this is due to the fact that when running in continuous batching mode, on average a larger batch of sequences is being processed at a time, leading to more cache evictions.
Our next step is to try to improve the cache hit rate which we can do by grouping common prefixes together. A simple way to do this is to just globally sort the data which is what we do next.
Sorting
For this method, we run the same continuous batching technique, along with a synchronous global sort of the data at the start of the workload. This ensures that for the most part, prompts with common prefixes end up in the same batch.
Synchronously sorting the data and then running the continuous batching method takes 563 seconds and yields a 35.2% speedup relative to just continuous batching. We can also verify this due to better caching by looking at the cache hit rate which increases from 26.5% to 54.5%. This means that more than half of the input tokens leverage caching now.
One of the downsides of this method is that our GPUs sit idle while the distributed sort is happening. Our next attempt is do both the continuous batching inference and prefix grouping at the same time so that our GPUs are doing useful work for the full workload. We do this by relaxing the requirement of globally sorting the data and use the Dynamic Prefix Bucketing scheme that we previously discussed.
Dynamic Prefix Bucketing
By employing Dynamic Prefix Bucketing locally and Prefix-Aware Routing globally, we are able to avoid the GPU idle time caused by the global sort, while still achieving good prefix cache hit rates across the cluster. In this method, we also make use of continuous batching, sending prefix-bucketed prompts to the inference input buffers in a streaming fashion.
Our Dynamic Prefix Bucketing method took 482 seconds which is a 12.7% speedup relative to the synchronous global sort method, and a 50.7% total speedup over our baseline. Furthermore, we are able to maintain our cache hit rate at 54%. This means that Dynamic Prefix Bucketing only has a cache hit rate penalty of 0.5% compared to globally sorting the data, while having the ability to be pipelined with LLM inference!
Ray Data
As an additional baseline, we use Ray Data with their off-the-shelf ray.data.llm batch processing APIs [1]. Since it also uses vLLM under the hood, we were able to set it to the exact same configurations as our own benchmarking scripts. The one thing we changed was the batch size, which we set to 16, since we observed that a smaller batch size performed better on their setup.
With Ray Data, we observe a runtime of 842 seconds, which is similar to our continuous batching method. Since Ray Data also utilizes continuous batching, this validates the performance of our methods.


Scalability
We next test the scalability of Daft with Dynamic Prefix Bucketing and Ray Data.
To do this we run both systems on our 32, 64, and 128 GPU configuration and measure the wall time. From this we can derive the scaling factor of how well the systems scale when we increase cluster sizes.
For Daft, we see near linear scaling from going from 32 to 64 GPUs and then a 87% efficiency when going from 32 to 128 GPUs. At this point, we notice that the overhead of downloading model weights and initialization of the model on GPU (all 128 of them) is now the bottleneck for improving scalability since it is a constant cost.
We also see that in all configurations below Daft with Dynamic Prefix Bucketing is slightly more scalable than Ray Data.
| Daft Runtime (s) | Daft Speedup (vs 32 GPU) | Daft Scaling Factor (vs 32 GPU) | Ray Data Runtime (s) | Ray Data Speedup (vs 32 GPU) | Ray Data Scaling Factor (vs 32 GPU) | |
|---|---|---|---|---|---|---|
| 32 GPUs | 1682 | 1 | 1 | 2915 | 1 | 1 |
| 64 GPUs | 865 | 1.94 | 0.97 | 1548 | 1.88 | 0.94 |
| 128 GPUs | 481 | 3.49 | 0.87 | 842 | 3.46 | 0.86 |

Ablation on Prefix Count
Finally we see how Daft with Dynamic Prefix Bucketing adapts to different dataset with varying number of prefixes. Here we sweep the number of unique prefixes in a 102M token data with 200k prompts.
Here we see that Dynamic Prefix Bucketing works better when there are more entries of a common prefix in the dataset. We see that the more common a prefix is the faster the workload runs and the cache hit rate is higher.


Future Work
The vLLM Prefix Caching model provider is available to try today. Below are some future improvements that we would like to make to the implementation.
Beyond text generation
The vLLM Prefix Caching provider currently only supports text generation with our prompt function, but the same techniques described in this post can also be applied to embedding generation and structured outputs.
Smarter load balancing
The router currently load balances using the number of prompts sent to each serving engine replica. This assumes that all GPUs are equally as fast and that sequences take around the same time to generate, which may not be true in real-world scenarios. Instead, the router should monitor the actual number of unfinished requests on each replica to better load balance.
More accurate cache modeling
The router estimates the prefix cache on each replica via a bounded queue of sent prefixes for each replica. We found that this is already very effective, but a more accurate model of the prefix caches or a method to inspect the cache metrics on serving engines would improve the ability to route batches to the best replica.
Further improve scaling
We should investigate the current bottlenecks for scaling the system to larger clusters. In theory it should be possible to achieve super-linear scaling, where 2x more GPUs can achieve more than 2x speedup, since a larger cluster will have a larger total prefix cache.
In addition, we welcome your feedback on these features! Let us know how we can improve Daft and what you would like to see, by submitting an issue on Github or sending us a message on our community Slack.
Appendix
[1] We encountered an issue using Ray Data's build_llm_processor where we would get an error about no running async event loop. We were able to resolve this issue by downgrading our uvloop version to v0.21.

