
After the First Run
Using Daft's observability tools to uncover performance pitfalls
by Srinivas LadeDeveloping AI workloads can be a complex and iterative process. Often, the initial implementation of an AI pipeline, while functionally correct, might suffer from unexpected bottlenecks or scale imperfectly. Identifying and resolving these issues can be a time-consuming and frustrating endeavor.
At Eventual, we're building Daft to be the foremost engine for running models on data. Thus, while performance is critical, our priority is reducing the time it takes to successfully implement a workload. To this end, we have developed a variety of tools for lightweight profiling during development. This blog post will demonstrate how one could utilize these tools while building a Daft pipeline.
Watch a quick 3 minute tutorial
Developer Advocate ChanChan Mao walks through the 3 key steps mentioned in this blog post to show you exactly how to identify bottlenecks and optimize your data processing pipeline.
Let's look at a (fun) example
I recently moved to San Francisco, so in order to force myself to explore the city, I've been going to various parks in different neighborhoods. Since SF is a very dog-friendly city, there have been a bunch of dogs playing around at every park I visit. So I thought a fun mini-project would be to figure out what breeds are the most common to find in the city.
To get started, I found and saved a bunch of pictures of SF dog parks, as many as I could find. I then wrote a simple Python function that:
- For each image: Look for and detect dogs in the image using the Huggingface moondream2 model
- For each dog:
- Crop the image around the dog and save it
- Give the image to the OpenAI visions API and ask it "What's the breed of the dog in this picture?"
With some trial-and-error, I was able to get this simple script working for a single image:
from io import BytesIO
import os
import base64
from uuid import uuid4
from transformers import AutoModelForCausalLM
from PIL import Image
import openai
# Model for object detection
model = AutoModelForCausalLM.from_pretrained(
"vikhyatk/moondream2",
revision="2025-06-21",
trust_remote_code=True,
device_map={"": "mps"}
)
# OpenAI client for dog breed detection
client = openai.OpenAI(api_key=os.environ["OPENAI_KEY"])
def analyze_image(path):
"""
Given a file path to an image:
1) Find all dogs in the image
2) Crop and save the image around the dog
2) Identify their breed
"""
original_image = Image.open(path)
output = model.detect(original_image, "dog")
descriptions = []
for bbox in output["objects"]:
x_min = int(bbox["x_min"] * original_image.width)
y_min = int(bbox["y_min"] * original_image.height)
x_max = int(bbox["x_max"] * original_image.width)
y_max = int(bbox["y_max"] * original_image.height)
image = original_image.crop((x_min, y_min, x_max, y_max)).resize((854, 480))
byte_buffer = BytesIO()
image.save(byte_buffer, format='JPEG')
png_bytes = byte_buffer.getvalue()
out_name = f"images/{uuid4()}.jpeg"
with open(out_name, "wb") as f:
f.write(png_bytes)
b64_image = base64.b64encode(png_bytes).decode("utf-8")
response = client.responses.create(
model="gpt-4o-mini",
input=[
{
"role": "user",
"content": [
{"type": "input_text", "text": "What dog breed does this look like? Best guess. Name only"},
{"type": "input_image", "image_url": f"data:image/jpeg;base64,{b64_image}"}
],
}
],
)
descriptions.append({"description": response.output[0].content[0].text, "image_out": out_name})
return descriptionsAfter analyzing, this is what we get:


Awesome, it works! At this point, I thought it would be great if I could scale up my code with Daft. Plus, I could use its built-in operations for listing all the images I have. Daft makes it very easy to take arbitrary Python code and run it in a pipeline using the user-defined-function (UDF) API. This was my initial version:
from io import BytesIO
import os
import base64
from uuid import uuid4
from transformers import AutoModelForCausalLM
from PIL import Image
import openai
import daft
from daft import col, DataType
@daft.udf(return_dtype=list[{
"description": str,
"cropped": str,
"bbox": DataType.fixed_size_list(DataType.uint64(), 4),
}])
class MassiveUDF():
def __init__(self):
self.model = AutoModelForCausalLM.from_pretrained(
"vikhyatk/moondream2",
revision="2025-06-21",
trust_remote_code=True,
device_map={"": "mps"}
)
self.client = openai.OpenAI(api_key=os.environ["OPENAI_KEY"])
def run_one(self, path):
original_image = Image.open(path.removeprefix("file://"))
output = self.model.detect(original_image, "dog")
descriptions = []
for bbox in output["objects"]:
x_min = int(bbox["x_min"] * original_image.width)
y_min = int(bbox["y_min"] * original_image.height)
x_max = int(bbox["x_max"] * original_image.width)
y_max = int(bbox["y_max"] * original_image.height)
image = original_image.crop((x_min, y_min, x_max, y_max)).resize((854, 480))
byte_buffer = BytesIO()
image.save(byte_buffer, format='JPEG')
jpeg_bytes = byte_buffer.getvalue()
out_name = f"images/{uuid4()}.jpeg"
with open(out_name, "wb") as f:
f.write(jpeg_bytes)
b64_image = base64.b64encode(jpeg_bytes).decode("utf-8")
response = self.client.responses.create(
model="gpt-4o-mini",
input=[
{
"role": "user",
"content": [
{"type": "input_text", "text": "What dog breed does this look like? Best guess. Name only"},
{"type": "input_image", "image_url": f"data:image/jpeg;base64,{b64_image}"}
],
}
],
)
descriptions.append({
"description": response.output[0].content[0].text,
"cropped": out_name,
"bbox": [x_min, y_min, x_max - x_min, y_max - y_min],
})
return descriptions
def __call__(self, images):
return [self.run_one(image) for image in images]
df = daft.from_glob_path("sources/*.jpeg")
df = df.with_column("output", MassiveUDF(col("path")))
df = df.explode("output").select(
col("path").alias("original"),
col("output")["bbox"],
col("output")["cropped"],
col("output")["description"],
)
df.show(n=25, max_width=50)But when I ran it via python detect.py, it was annoyingly slow. For just 6 images with 25 dogs in total, it took more than a minute. Plus, looking at htop, I could see that I'm barely using my CPU cores.

What's going on? Looking at the progress bar, I don't see much going on, so I'm not sure what to do next.

Using Daft as a code wrapper
You may have run into a similar issue when first using Daft. Since Daft makes it easy to include UDFs, it's very easy to just dump all of your code into a single UDF and call it a day.
This isn't necessarily a bad approach. Given a UDF, the underlying Daft execution engine can spin up multiple instances of the code and run them in parallel.
However, Daft does not modify the Python code inside of UDFs, effectively treating them as black boxes. While that helps ensure correctness, it makes it more difficult to see what's actually going on. In our case, without starting to add some timers and print statements, we don't know why the massive UDF takes so long.
So how can I go about profiling and optimizing my script?
Thankfully, Daft comes with a variety of first-class tools to profile your code and help you find bottlenecks. For example, you may have seen the progress bar that appears when we run a Python script from the command line. In addition, there is a profiling tool available.
In general, there are 3 tips to optimizing your code:
- Break UDFs down into smaller pieces
- Rewrite UDFs into native Daft expressions
- Tune your UDFs
Let's go through these steps 1-by-1 to see how they can help you iterate on your workflow to take full advantage of Daft.
1) Break UDFs down into smaller pieces
By splitting UDFs into smaller pieces, Daft will have more awareness about the flow of operations in your workload and can make better decisions. Not only can Daft now track metrics between the different UDFs, but it can also identify potential bottlenecks and allocate more resources. For example, if you have two UDFs, udf_a and udf_b, where udf_b takes significantly longer, then the engine will run more instances of udf_b and fewer of udf_a.
Note that in order to split the UDF into pieces, you need to know the types of the data that pass between, since Daft has to serialize the data in between. This can be a good indicator of where it makes most sense to split the function.
Let's take our code and break it down into much smaller pieces.
from io import BytesIO
import os
import base64
from uuid import uuid4
from transformers import AutoModelForCausalLM
from PIL import Image
import openai
import daft
from daft import col, DataType
@daft.udf(return_dtype=DataType.image())
def load_image(paths):
return [Image.open(path.removeprefix("file://")) for path in paths]
@daft.udf(return_dtype=DataType.list(DataType.fixed_size_list(DataType.uint64(), 4)))
class DetectDogs:
def __init__(self):
self.model = AutoModelForCausalLM.from_pretrained(
"vikhyatk/moondream2",
revision="2025-06-21",
trust_remote_code=True,
device_map={"": "mps"}
)
def run_one(self, image):
image = Image.fromarray(image)
output = self.model.detect(image, "dog")
bboxes = []
for bbox in output["objects"]:
x_min = int(bbox["x_min"] * image.width)
y_min = int(bbox["y_min"] * image.height)
x_max = int(bbox["x_max"] * image.width)
y_max = int(bbox["y_max"] * image.height)
bboxes.append([x_min, y_min, x_max, y_max])
return bboxes
def __call__(self, images):
return [self.run_one(image) for image in images]
@daft.udf(return_dtype=DataType.binary())
def crop_dog_to_jpeg(images, bboxes):
outputs = []
for image, bbox in zip(images, bboxes):
cropped = Image.fromarray(image).crop(tuple(bbox)).resize((854, 480))
byte_buffer = BytesIO()
cropped.save(byte_buffer, format='JPEG')
outputs.append(byte_buffer.getvalue())
return outputs
@daft.udf(return_dtype=DataType.string())
class IdentifyBreed():
def __init__(self):
self.client = openai.OpenAI(api_key=os.environ["OPENAI_KEY"])
def run_one(self, image_jpeg: bytes):
b64_image = base64.b64encode(image_jpeg).decode("utf-8")
response = self.client.responses.create(
model="gpt-4o-mini",
input=[
{
"role": "user",
"content": [
{"type": "input_text", "text": "What dog breed does this look like? Best guess. Name only"},
{"type": "input_image", "image_url": f"data:image/jpeg;base64,{b64_image}"}
],
}
],
)
return response.output[0].content[0].text
def __call__(self, images):
return [self.run_one(image) for image in images]
@daft.udf(return_dtype=DataType.string())
def save_image(image_jpegs):
outputs = []
for image_jpeg in image_jpegs:
out_name = f"images/{uuid4()}.jpeg"
with open(out_name, "wb") as f:
f.write(image_jpeg)
outputs.append(out_name)
return outputs
df = daft.from_glob_path("sources/*.jpeg")
df = df.with_column("image", load_image(col("path")))
df = df.with_column("bbox", DetectDogs(col("image")).explode())
df = df.with_column("dog_image", crop_dog_to_jpeg(col("image"), col("bbox")))
df = df.with_column("description", IdentifyBreed(col("dog_image")))
df = df.with_column("cropped", save_image(col("dog_image")))
df = df.select(
col("path").alias("original"),
col("bbox"),
col("cropped"),
col("description"),
)
df.show(n=25, max_width=50)While the code does look longer, it's easier to see the flow of steps at the bottom. Plus, the steps now appear in the progress bar!
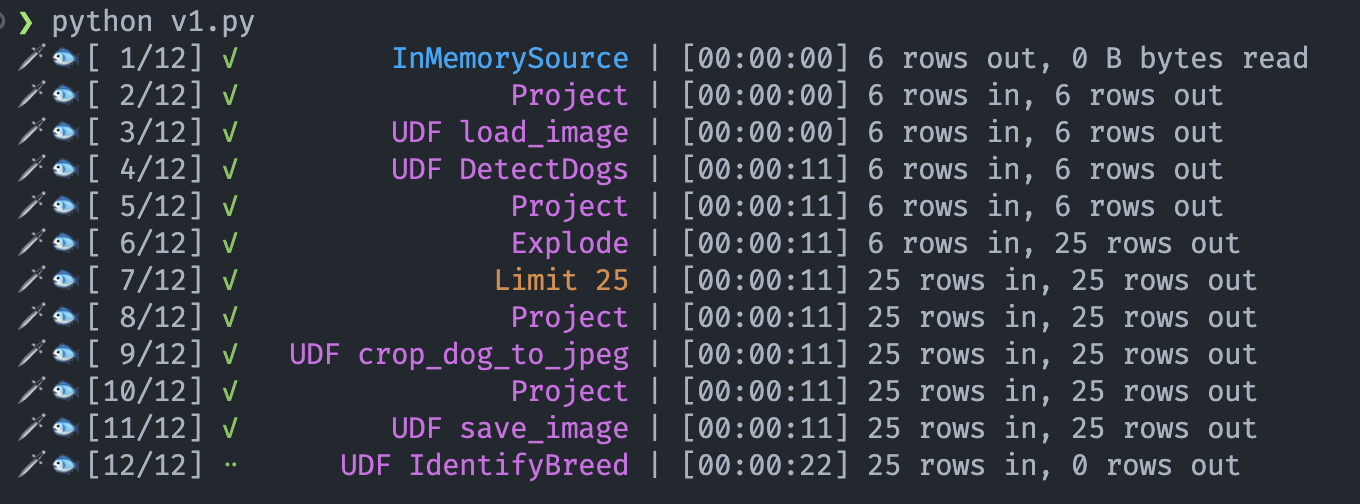
It can be hard at this point to track how long each step takes, particularly the really short ones. For this case, Daft provides a profiling tool that will track runtimes of operators and write them out to a Markdown using Mermaid for a diagram. You can enable it via the environment variable DAFT_DEV_ENABLE_EXPLAIN_ANALYZE=1. If we rerun with it enabled, we get this profile out:
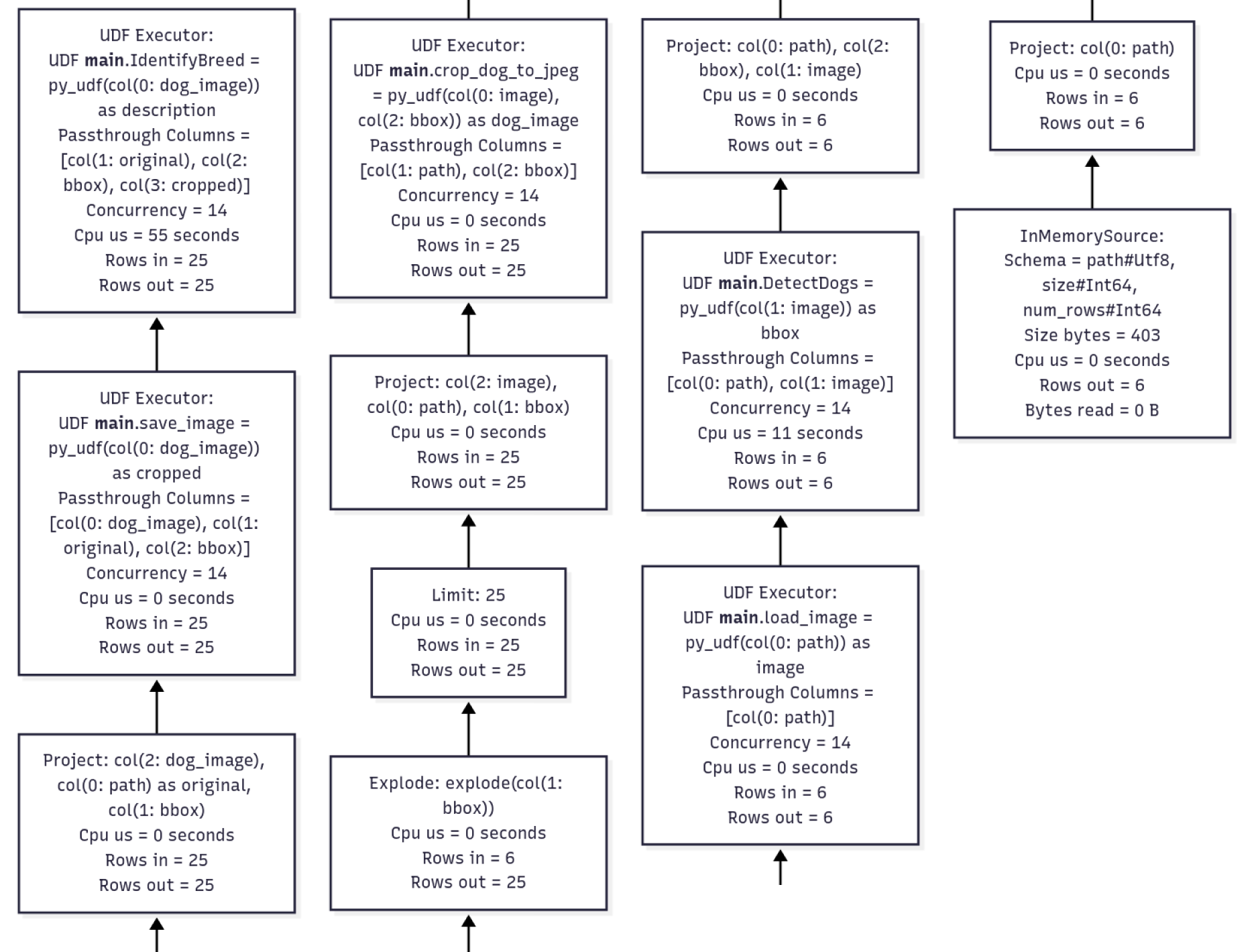
From this, we can quickly identify that the OpenAI call to identify the breed takes the longest. What can we do from here?
2) Use native Daft functions
In addition to orchestrating your AI pipeline, Daft comes with built-in functions for many common data operations, particularly on multimodal data. These functions are often written in Rust with performance in mind, battle-tested at scale, and can be simpler to use than a custom UDF. Let's rewrite our pipeline with Daft functions and try that.
import base64
import os
from transformers import AutoModelForCausalLM
from PIL import Image
import openai
import daft
from daft import col, DataType
@daft.udf(return_dtype=DataType.list(DataType.fixed_size_list(DataType.uint64(), 4)))
class DetectDogs:
def __init__(self):
self.model = AutoModelForCausalLM.from_pretrained(
"vikhyatk/moondream2",
revision="2025-06-21",
trust_remote_code=True,
device_map={"": "mps"}
)
def run_one(self, image):
image = Image.fromarray(image)
output = self.model.detect(image, "dog")
bboxes = []
for bbox in output["objects"]:
x_min = int(bbox["x_min"] * image.width)
y_min = int(bbox["y_min"] * image.height)
x_max = int(bbox["x_max"] * image.width)
y_max = int(bbox["y_max"] * image.height)
# Need width and height
bboxes.append([x_min, y_min, x_max - x_min, y_max - y_min])
return bboxes
def __call__(self, images):
return [self.run_one(image) for image in images]
@daft.udf(return_dtype=DataType.string())
class IdentifyBreed():
def __init__(self):
self.client = openai.OpenAI(api_key=os.environ["OPENAI_KEY"])
def run_one(self, image_jpeg: bytes):
b64_image = base64.b64encode(image_jpeg).decode("utf-8")
response = self.client.responses.create(
model="gpt-4o-mini",
input=[
{
"role": "user",
"content": [
{"type": "input_text", "text": "What dog breed does this look like? Best guess. Name only"},
{"type": "input_image", "image_url": f"data:image/jpeg;base64,{b64_image}"}
],
}
],
)
return response.output[0].content[0].text
def __call__(self, images):
return [self.run_one(image) for image in images]
df = daft.from_glob_path("sources/*.jpeg")
df = df.with_column("image", col("path").url.download().image.decode())
df = df.with_column("bbox", DetectDogs(col("image")).explode())
df = df.with_column("dog_image", col("image").image.crop(col("bbox")).image.resize(854, 480).image.encode("jpeg"))
df = df.with_column("description", IdentifyBreed(col("dog_image")))
df = df.with_column("cropped", col("dog_image").url.upload("images"))
df = df.select(
col("path").alias("original"),
col("bbox"),
col("cropped"),
col("description"),
)
df.show(n=25, max_width=50)Looks like we were able to rewrite a lot of the UDFs for working with images into Daft functions; the only remaining ones are for detection and inference. At a minimum, the script is simpler to follow now. However, since the bottleneck was in the OpenAI inference, we don't see much of a speedup in our profile.
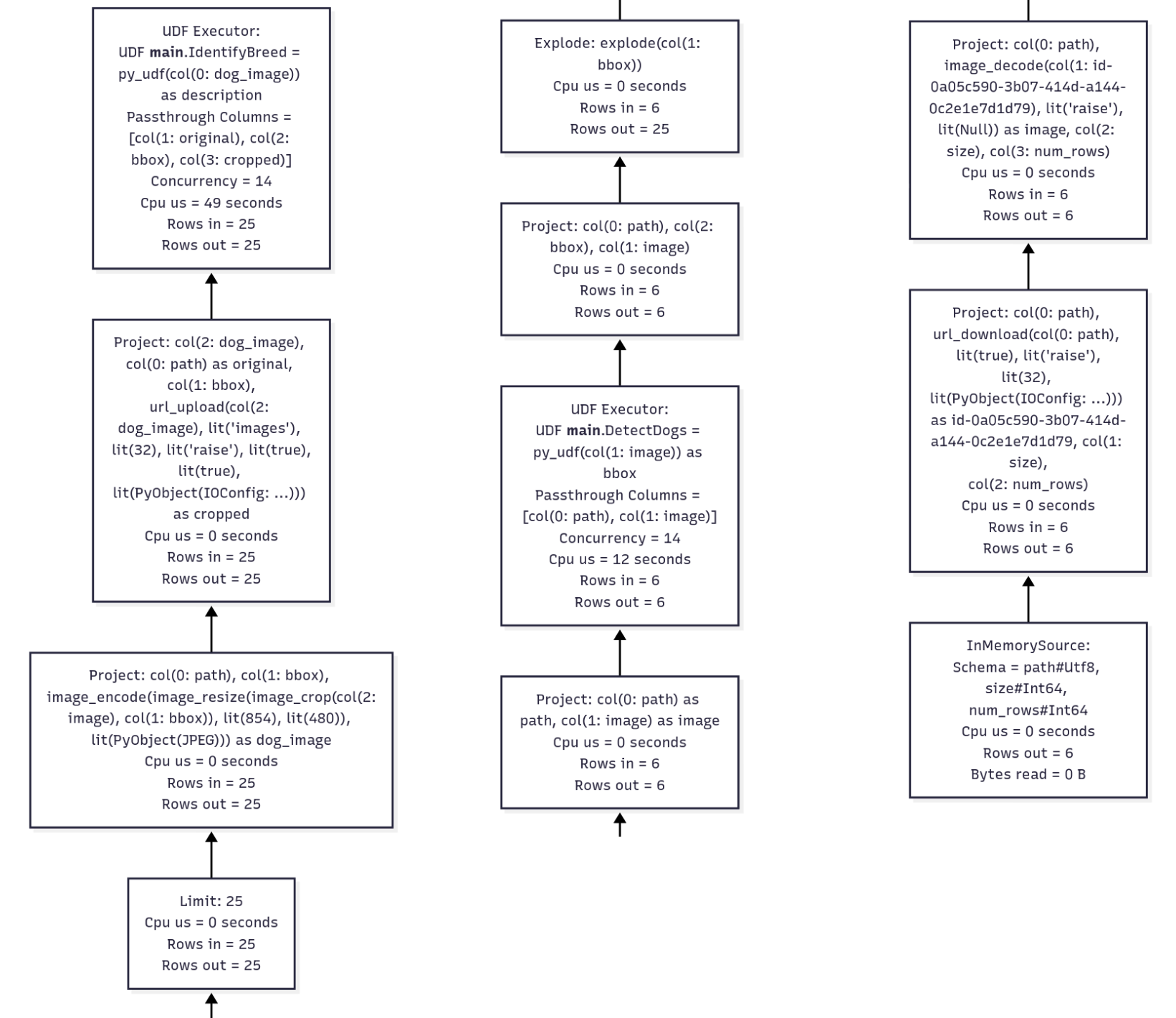
3) Tune your UDFs
Now that we've converted some of our UDFs into native Daft expressions, we're left with code that we have to keep in Python. So what do we do? For situations like this, Daft provides additional variants and parameters for UDFs to tune them to your specific use-case.
Using the right function variant for the situation
Depending on the type and return value of the function, Daft can perform additional optimizations at execution time. For example, if the function is async, the engine can run more instances concurrently. In our case, UDF DetectDogs returns a list of values, but we could alternatively write it as a generator function so we can process more iteratively.
# Replacing DetectDogs UDF with a generator function
model = AutoModelForCausalLM.from_pretrained(
"vikhyatk/moondream2",
revision="2025-06-21",
trust_remote_code=True,
device_map={"": "mps"}
)
@daft.func(return_dtype=DataType.fixed_size_list(DataType.uint64(), 4))
def detect_dogs(image: Image.Image):
image = Image.fromarray(image)
output = model.detect(image, "dog")
for bbox in output["objects"]:
x_min = int(bbox["x_min"] * image.width)
y_min = int(bbox["y_min"] * image.height)
x_max = int(bbox["x_max"] * image.width)
y_max = int(bbox["y_max"] * image.height)
# Need width and height
yield [x_min, y_min, x_max - x_min, y_max - y_min]Set UDF parameters
If you want to go the extra mile, the daft.udf decorator has additional parameters to tune how it will be executed. Most of the parameters, like concurrency, num_gpus, and memory_bytes help reduce contention and potential OOMs by limiting the number of concurrently running instances.
But for our case, we want to tune the batch_size parameter, which controls the number of rows provided as input to the function. Smaller batch sizes can help parallelize smaller workloads like our case, while larger batch sizes can reduce overhead and maximize throughput. Since we're working with a few dozen rows, let's set batch_size=1.
With our changes, our workload finished in 24s; we made it 3x faster! Note that even though the profile states that IdentifyBreed took longer, it was executed concurrently, so overall it was faster.
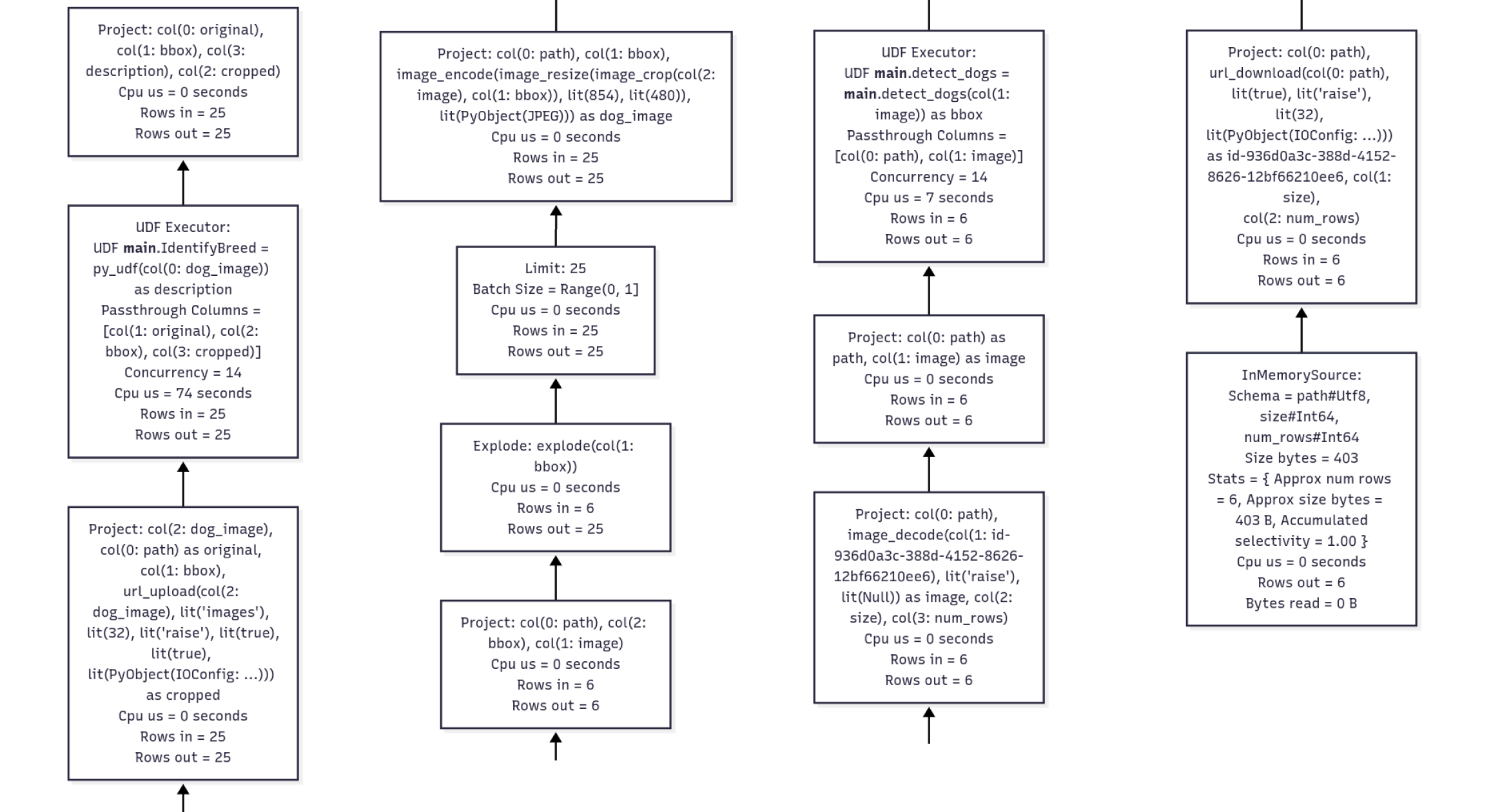
Note: In reality, you may perform these three steps in any order and multiple times throughout the development process, depending on what your bottleneck actually is and if you're happy with the performance. But the general idea of iterative development still applies.
What's next?
Now with a robust foundation, we can start experimenting with larger changes, such as:
- Using different models for object detection, such as YOLO
- Trying out a locally hosted image model for classification to avoid those OpenAI API costs
- Annotating the input image with bounding boxes and labels for each dog
Generally speaking, this 3-stage approach, paired with our built-in observability and profiling tools, allows developers to quickly identify bottlenecks and iterate, whether running on a single laptop or at scale.
We encourage you to explore Daft further and apply these techniques to your own AI workloads. Check us out on Github, follow us on LinkedIn, and join us on Slack.

