
Announcing Early Access to Daft Cloud
Early access to Daft Cloud for running model-driven AI pipelines reliably at production scale. Built on Daft OSS for continuous, resilient execution.
by Jay Chia, Steffi LiAgents and AI-powered features are beginning to deliver real value in production systems.
What those systems depend on, however, is not just model intelligence, but timely, rich, and accurate data as context. That dependency is easy to ignore in demos, notebooks, and agent eval benchmarks, but it becomes unavoidable in production, where models must run reliably, repeatedly, and at scale.
Most AI infrastructure does not fail because model code is hard to write.
It fails because operating model-driven data pipelines at scale is treated like a side effect.
Running embeddings, extraction, and enrichment over real data is fundamentally different from running joins and aggregations. The work is more expensive, failures are expected, and throughput matters far more than latency.
At the production scale, those differences show up as familiar operational failures such as rate limits, GPU availability, and error handling over complex multimodal data processing.
The problem we kept seeing
Data is read from object storage or a warehouse/data lake. Some preprocessing happens in Spark. One or more models are called. Results are written to a vector database or downstream table.
Conceptually simple. Operationally painful.
Rate limits stall jobs. Small failure rates trigger full re-runs. Unchanged data gets reprocessed because incremental execution is hard to reason about. Observability stops at the job level, even though the real failures happen at the row level.
Teams make it work, but only by building a lot of infrastructure themselves.
Why open source was not enough
For the past four years, we have been building Daft in the open. Hundreds of teams have used the open source engine to process multimodal data, prepare datasets, and prototype AI pipelines. Along the way, we learned a lot about where the real pain actually lives.
Open source can give you a powerful execution engine. It cannot give you a shared inference runtime at production scale. It cannot manage GPU lifecycles, global rate limits, or multi-tenant batching. It cannot provide end-to-end visibility into retries, failures, and cost across runs.
Teams would use Daft OSS to express their pipelines cleanly, then spend weeks rebuilding everything around it to make those pipelines production-safe. Orchestration. Autoscaling. Retries. Observability. Cost controls.
Daft Cloud exists because some parts of this problem only make sense as a managed system. The engine stays open. The runtime becomes shared.
Daft Cloud in a diagram
If you imagine the Daft architecture as a simple flow, it looks like this
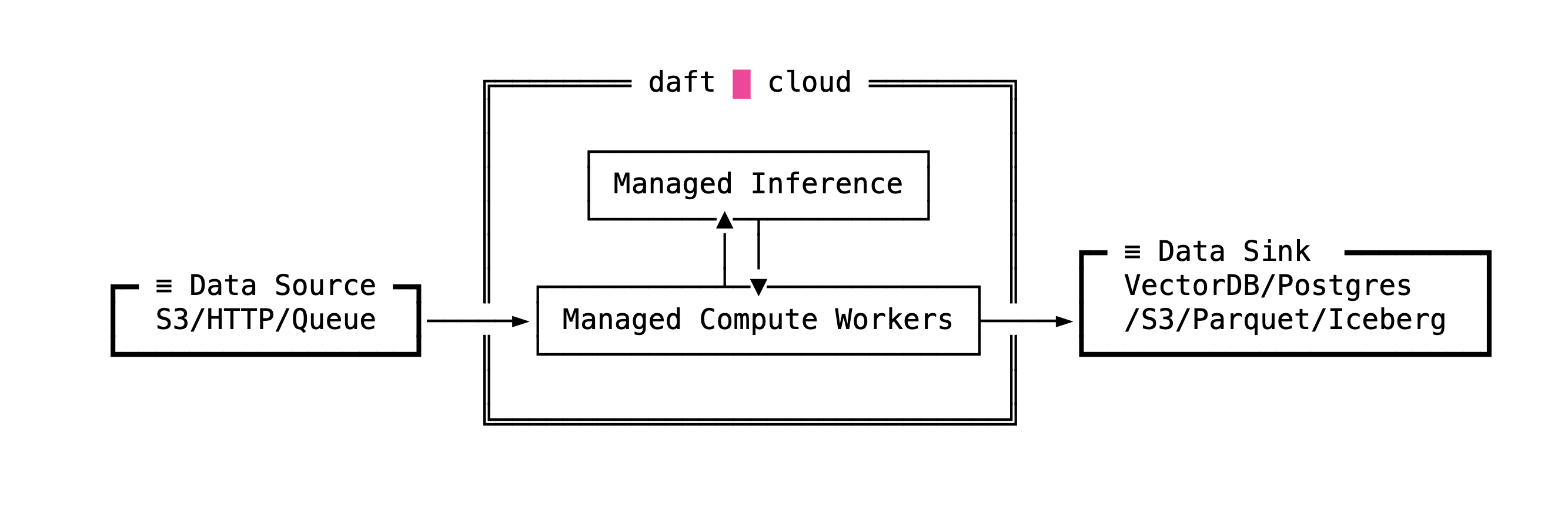
Sources flow into Daft. Daft applies model-aware transforms. Outputs are kept continuously up to date as data changes.
The interesting part is what happens inside that middle box.
Daft Cloud is a serverless runtime for model-driven data pipelines, built on top of the Daft open source engine. There are no clusters to provision, no executors to tune, and no long-running infrastructure to keep alive. Pipelines scale up to match data volume, scale down when idle, and continue running through partial failures without operator intervention.
Daft Cloud combines the Daft OSS engine with a managed runtime that handles:
- How to stream data through models
- How to batch and backpressure inference calls
- How to isolate failures to individual records
- How to avoid recomputing work that has not changed
Instead of stitching together orchestration, compute, and inference yourself, the system does it end-to-end.
Early access
Daft Cloud is in early access because this problem cannot be solved correctly in the abstract or in isolation.
We want to work with teams who:
- Have real data volumes
- Run real production pipelines
- Care deeply about reliability, cost, and iteration speed
Early access means:
- The core execution model is stable and in use
- We onboard teams directly and learn from real workloads
- Some capabilities are still evolving based on feedback
- Not everything is fully self-serve yet
This is intentional. We would rather get the fundamentals right than ship a polished UI on top of the wrong abstractions.
What early users are doing today
One early access team is a large consumer platform with millions of creator-generated posts and images. Their ML infrastructure powers ranking, retrieval, and discovery systems that depend heavily on embeddings and multimodal understanding.
Before Daft Cloud, their pipeline was built on Databricks, with thousands of lines of Spark UDFs handling inference. They had custom logic for batching, rate limiting, retries, and schema handling. Separate systems for batch and online inference. Full re-runs when a small fraction of rows failed.
The system worked, but it was fragile and slow to evolve.
With Daft Cloud, they started with a small slice of real data, then scaled to millions of rows.
What changed was not the model code. It was everything around it.
Inference became streaming instead of stage-based. Failures were isolated to individual rows. Backpressure was handled automatically across storage, models, and sinks. The same pipeline ran locally for development and at scale in production.
They are now evaluating multimodal embedding quality, comparing models, and incrementally scaling toward millions of records, without rewriting their pipeline or rebuilding their infrastructure.
That is the workload Daft Cloud is built for.
Why this is different from existing stacks
Daft Cloud is not a general-purpose data platform with AI features added later.
It is built around a few strong opinions.
-
Model transforms are first-class. Embeddings and LLM calls are native operations, not opaque Python functions. This allows the system to batch intelligently, retry safely, and apply backpressure end-to-end.
-
Execution is streaming and serverless. Data flows continuously from source to model to sink. We do not load everything, then process everything, then write everything.
-
Failure is normal, not exceptional. Long-running pipelines expect partial failure. Failed rows can be inspected and replayed without restarting the world.
-
Incremental work matters. Only new or changed data is processed. Embedding caches and deduplication avoid unnecessary model calls.
-
Development and production share the same code. Pipelines written in Daft OSS run locally and in Daft Cloud without modification.
These choices are a direct continuation of the ideas behind Daft itself.
Who this is for, and who it is not
Daft Cloud early access is for teams who:
- Run batch inference at scale
- Process large volumes of unstructured or multimodal data
- Have outgrown Spark UDFs and custom orchestration
- Care about throughput, reliability, and cost visibility
It is not for:
- Prompt playgrounds
- Notebook-only experimentation
- Real-time serving or agent frameworks
We are focused on one thing: making model transforms on data boring, predictable, and cheap to run.
Shaping what comes next
Early access users are shaping Daft Cloud in very concrete ways.
We are actively working with them on:
- Programmatic APIs for launching and monitoring runs
- Model lifecycle management, including custom and open models
- Failure handling, replay, and row-level observability
- Cost and performance metrics that drive real decisions
These are not hypothetical features. They are responses to real pipelines running today.
Getting access
Early access is currently invitation-based. We onboard teams directly, learn about their workloads, and get meaningful pipelines running quickly.
If you are running, or about to run, large-scale model transforms on real data and want to see whether Daft Cloud is a fit, request a demo.
We would love to talk.

