
Daft v0.7.8: Dashboard Heatmaps, Vectorized GroupBy, and Native Image Hashing
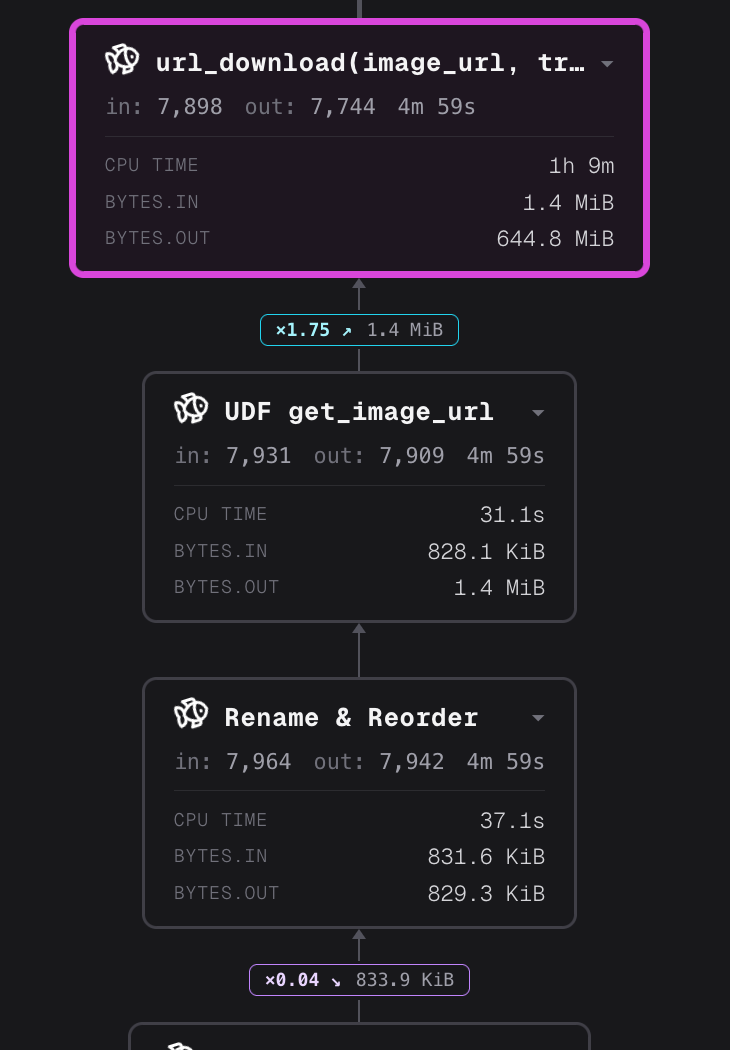
Daft's query dashboard now shows you exactly where time is going. Slow operators light up red, completed nodes turn green, and arrows trace the data flow through your pipeline. No more guessing which
by Daft TeamDaft's query dashboard now shows you exactly where time is going. Slow operators light up red, completed nodes turn green, and arrows trace the data flow through your pipeline. No more guessing which stage is the bottleneck.
Under the hood, grouped aggregations got a full rewrite — a new vectorized path replaces per-group index lists with dense group-id arrays and tight accumulator loops, delivering up to 4.4x faster groupbys at high cardinality. And image_hash() ships as a first-class function: eight perceptual hashing algorithms implemented in Rust, bit-exact with the Python imagehash library, for large-scale image deduplication without custom UDFs.
Dashboard Heatmaps and Pipeline Direction
The Daft query dashboard now visualizes operator performance in real time. @universalmind303 added heatmap coloring that maps each operator node to a color based on its execution time — slow operators glow red, and completed nodes transition to green (#6628).
A companion PR adds directional arrows between nodes so you can trace data flow through the pipeline at a glance (#6625).
Together these turn the dashboard from a static topology view into a live execution monitor. When a query is running, you see the hot path immediately — no need to scrub through JSONL event logs or guess which operator is stalling.
Vectorized Grouped Aggregation
The standard agg_groupby path materializes per-group index lists — Vec<Vec<u64>> — during make_groups(), then iterates each group's indices to compute the aggregate. At low cardinality that's fine. At high cardinality it means millions of small heap allocations and scattered memory access.
@desmondcheongzx rewrote this as a two-phase vectorized path (#6345):
Phase 1 (hash probe): A single pass over the groupby columns builds a dense group_ids: Vec<u32> mapping each row to its group, plus group_sizes: Vec<u64> for per-group row counts.
Phase 2 (vectorized accumulation): Each accumulator runs a tight loop over the dense group_ids array:
Old path:
Group A: [0, 2, 4] → vals[0] + vals[2] + vals[4] // scattered access
Group B: [1, 3] → vals[1] + vals[3]
New path:
group_ids = [0, 1, 0, 1, 0]
for (gid, val) in group_ids.zip(vals):
sums[gid] += val // sequential access
Count accumulators skip the scatter loop entirely, using pre-computed group_sizes from Phase 1. Accumulators use an AggAccumulator enum instead of trait objects to avoid vtable dispatch in the hot loops.
@BABTUNA extended the inline path with min/max accumulator types (#6604), bringing the full set to count, sum, min, and max. Min/max required per-type accumulator variants (unlike sum which widens to Int64), with NaN propagation matching the fallback path exactly.
@srilman then optimized the hash map layer (#6613): swapping FnvHashMap for HashBrown with foldhash, using SmallVec<[u64; 2]> to cut jemalloc deallocation overhead in make_groups, and restructuring list_agg to avoid millions of small vector allocations. The combined effect: a 4x improvement on connected components workloads (250s → 70s).
Benchmarks on ClickBench (c6a.4xlarge, 100 parquet files, ~100M rows):
| Query | Before | After | Speedup | Pattern |
|---|---|---|---|---|
| Q33 | 13.09s | 9.51s | 1.38x | GROUP BY WatchID, ClientIP (high cardinality) |
| Q18 | 2.56s | 1.83s | 1.40x | GROUP BY UserID, SearchPhrase |
| Q16 | 2.20s | 1.68s | 1.31x | GROUP BY UserID |
| Total (43 queries) | 118.4s | 106.6s | -10% |
The total ClickBench time dropped 10% below the v0.7.4 baseline — the first time the streaming engine has beaten the pre-regression numbers.
Native Image Hashing
v0.7.7 shipped the perceptual hashing internals. v0.7.8 ships the user-facing API.
@chenghuichen added image_hash() — a first-class Daft function for large-scale image similarity detection and deduplication (#6485):
from daft.functions import image_hash
df = daft.read_parquet("s3://my-bucket/images/")
df = df.with_column("hash", image_hash(df["image"], method="phash"))
# Find near-duplicates by grouping on hash
dupes = df.groupby("hash").count().where(df["count"] > 1)Eight algorithms are available:
| Algorithm | Best for |
|---|---|
| phash (default) | General-purpose — full 2D DCT, most robust |
| dhash | Fast structural comparison |
| ahash | Fastest — average hash |
| whash | Multi-level Haar wavelet |
| crop_resistant | Robust against cropping |
| colorhash | HSV color distribution |
All algorithms are implemented natively in Rust with an FFT-based DCT and multi-level Haar DWT. Results are bit-exact against the Python imagehash library. Batch hashing runs in parallel across all CPU cores via rayon, with the resize kernel operating on single-channel luma instead of RGB — together yielding 5-25x speedups over an equivalent Python UDF.
Null images produce null hashes, consistent with other Daft column operations. Closes #4889.
df.skip_existing() — Checkpoint-Based Deduplication
@everySympathy added df.skip_existing() for idempotent pipeline runs (#5931):
df = daft.read_parquet("s3://bucket/input/")
df = df.skip_existing(
existing_path="s3://bucket/output/",
key_column="id",
file_format="parquet",
)
df.write_parquet("s3://bucket/output/", write_mode="append")The operator reads keys from the output path and filters rows that have already been processed. Supports composite keys for pipelines where a single column isn't sufficient:
# RAG chunking pipeline — chunk_id is the dedup key
df = df.skip_existing(
existing_path="s3://bucket/output/",
key_column=["doc_id", "chunk_id"],
file_format="parquet",
)Currently supported on the distributed (Ray) runner. This addresses a long-standing request from the community (discussion #5868) — re-running ETL or RAG pipelines without reprocessing rows that already exist in the output.
Everything Else
- Subscriber API improvements — @srilman exposed nicer public APIs for working with subscribers, aimed at OpenLineage support (#6631). @cckellogg collapsed the subscriber trait to a single
on_eventmethod (#6593). - DataFrame.skew() and DataFrame.var() — @kerwin-zk added global aggregation convenience methods for skewness (#6619) and variance (#6584).
- Flotilla checkpoint wiring — @rohitkulshreshtha threaded
CheckpointIdfrom distributed task creation through the local execution layer, with a newStageCheckpointKeysOperatorthat stages key columns to the checkpoint store (#6567). - Catalog function support — @gavin9402 added a
get_functioninterface on the Catalog trait for resolving metastore-registered functions during planning (#6524). - Configurable Flotilla worker timeout — @desmondcheongzx replaced the hardcoded 120s actor startup timeout with
daft.set_execution_config(worker_startup_timeout=300)orDAFT_WORKER_STARTUP_TIMEOUTenv var (#6592). - Paimon DataSource migration — @chenghuichen migrated
PaimonScanOperatorto the new DataSource API (#6600). - Local shuffle disk read — @srilman made flight shuffle read local data directly from disk, bypassing the network stack (#6436).
- BatchManager consolidation — @universalmind303 consolidated BatchManager as a single buffer abstraction (#6566).
- Repartition exchange unification — @ohbh unified the repartition exchange write flow across Ray and Flight (#6499).
- Iceberg schema evolution fix — @sankarreddy-atlan fixed predicate evaluation against Parquet files that predate an Iceberg schema evolution — columns absent from old files no longer crash row group pruning or post-read filters (#6551).
- Ray nightly fix — @jeevb fixed nightly Daft version resolution in Ray runtime environments (#6630).
- Dashboard fixes — @samstokes fixed partition set passing for topology matching (#6576), smart per-node stats aggregation (#6574), and spurious Flotilla lifecycle events (#6573).
- IO retry on transient errors — @desmondcheongzx added retry for transient errors on initial GET requests (#6544).
- Byte range fix — @gweaverbiodev fixed the async reader skipping byte retrieval when range start equals end (#6602).
- Lance SQL filter docs — @Jay-ju added documentation for custom SQL filters in Lance (#5916).
Community Contributions
- @chenghuichen —
image_hash()with 8 algorithms, Paimon DataSource migration - @everySympathy —
df.skip_existing()checkpoint operator - @kerwin-zk —
DataFrame.skew(),DataFrame.var() - @BABTUNA — Min/max accumulator types for inline aggregation
- @gavin9402 — Catalog function support
- @sankarreddy-atlan — Iceberg schema evolution predicate fix
- @gweaverbiodev — Byte range IO fix
- @Jay-ju — Lance SQL filter documentation
- @yew1eb — Cargo workspace cleanup
Upgrade
uv add "daft>=0.7.8"Or try the latest nightly:
uv pip install daft --pre --extra-index-url https://nightly.daft.aiCheck the full changelog for the complete list of 34 merged PRs.

