
How Sourcetable Built the World's First AI Spreadsheet with Daft
Sourcetable CTO Andy Grosser discusses their data infrastructure choices and why reliability and scale drove their architecture decisions.
by YK SugiTwo billion people use spreadsheets. For most, they're constrained by rigid file size limits, disconnected data sources, and interfaces that haven't fundamentally changed in decades. Sourcetable set out to change that by building an AI-powered spreadsheet that can connect to any service on the internet and process gigabytes of data where competitors handle megabytes.
This post examines how Sourcetable built their data infrastructure to support thousands of users running complex queries across financial data, business analytics, and real-time external services, with Daft serving as the foundational layer of their processing stack.
The Product: Born from a Simple Problem
Sourcetable's origin story starts with co-founder Eoin McMillan doing contract work for construction companies. His job? Building spreadsheets. Specifically, he and a friend were hired to combine different datasets - essentially doing SQL joins manually through VLOOKUPs.
The insight was clear: this kind of data wrangling shouldn't require hiring specialists. The original mission became creating a system that could connect to any piece of data in the world and make it accessible to everyone - not just people with IT degrees, SQL skills, or VLOOKUP knowledge.
When CTO Andy Grosser joined, he brought a bet on AI that would prove prescient. "Before I started with the team, I was looking at BERT and a number of other pre-OpenAI LLMs," he recalls. "We started getting in very, very early." That early move made Sourcetable the first spreadsheet to bring AI to the masses, putting them six months to a year ahead of competitors.
Today, Sourcetable isn't just a spreadsheet with AI bolted on. It's a vertically integrated platform where users can:
Connect to any service online: HubSpot, banks, stock exchanges, Google Analytics, Gmail - thousands of integrations
Process real data at scale: 2GB per user vs. the 10-20MB limits of Excel and Google Sheets
Run specialized AI tools: Tens of thousands of expert tools, including 1000+ financial analysis tools built by CTO Andy (a former hedge fund engineer)
The results speak for themselves: one user completed their entire PhD - research, analysis, code, and paper - in under a week using Sourcetable. A third of their user base runs financial analyses, from options trading to market predictions.
The Infrastructure Challenges
Building a spreadsheet that connects to everything and processes gigabytes of data per user creates unique infrastructure challenges:
Diverse data sources: Users pull from uploaded CSVs, live APIs, databases, and web services - all in the same session
Reliability at scale: Thousands of users, each potentially running complex analytical queries
Future-proofing: Architecture that can scale from gigabytes today to petabytes tomorrow
As CTO Andy Grosser explains:
"We built Sourcetable along with the promise from Eventual to deal with petabyte scale. That said, our initial requirement is to deal with thousands of users dealing with gigabytes of data."
The Data Stack
Sourcetable's architecture centers on a few carefully chosen technologies, all running on AWS:
Storage Layer
Amazon S3: All data flows through S3 - whether uploaded by users or fetched in real-time from external services
Apache Cassandra: Handles all transactional (OLTP) workloads, chosen for proven reliability at massive scale
Processing Layer
Daft: The foundational data processing engine - every query touches Daft
DuckDB: Used alongside Daft for specific analytical workloads and its extensive plugin ecosystem
Ray: Orchestrates GPU scheduling, caching, and job management across the platform
Query Layer
Custom SQL Engine: Translates universal queries into operations across tables, files, workbooks, worksheets, and external services
The key architectural decision: everything flows through Daft first. Even when DuckDB is needed for specific plugins or analytics, Daft handles data ingestion and passes it to DuckDB - a workaround for DuckDB's reliability issues.
"There's a wicked combination between all of these - S3, Cassandra, Daft, Ray - that I would recommend to anybody who's starting a serious new startup."
Why Daft?
Before settling on Daft, Andy evaluated 30-40 alternatives including Spark, Snowflake, and HDFS. The decision came down to three factors:
1. Reliability
"I have not seen one bug for like 16 months. I cannot say that about DuckDB. I'm still dealing with fatal process shutdowns - you can't have a process shut down in the middle of processing."
DuckDB's segmentation faults when detaching databases in production forced Sourcetable to architect around its instability. Daft became the reliable foundation that DuckDB could safely sit on top of.
2. Performance
"Anybody who's used Spark before, you could wait 12 hours for a job to run. You could definitely do that in probably a couple of seconds with Daft. It's kind of a no-brainer."
At a previous company, Andy ran analytics queries on under a terabyte of data that took 12 hours and frequently failed with out-of-memory errors - even on cluster machines that should have handled the load. With Daft, equivalent operations would complete in seconds.
3. Future Scale
"I'm expecting that we're not going to have to do any more work to start processing 100,000 times more data."
The architecture is designed to grow. Starting with consumer-scale workloads (gigabytes), Sourcetable can expand to enterprise petabyte-scale without re-architecting their data layer.
The Architecture in Practice
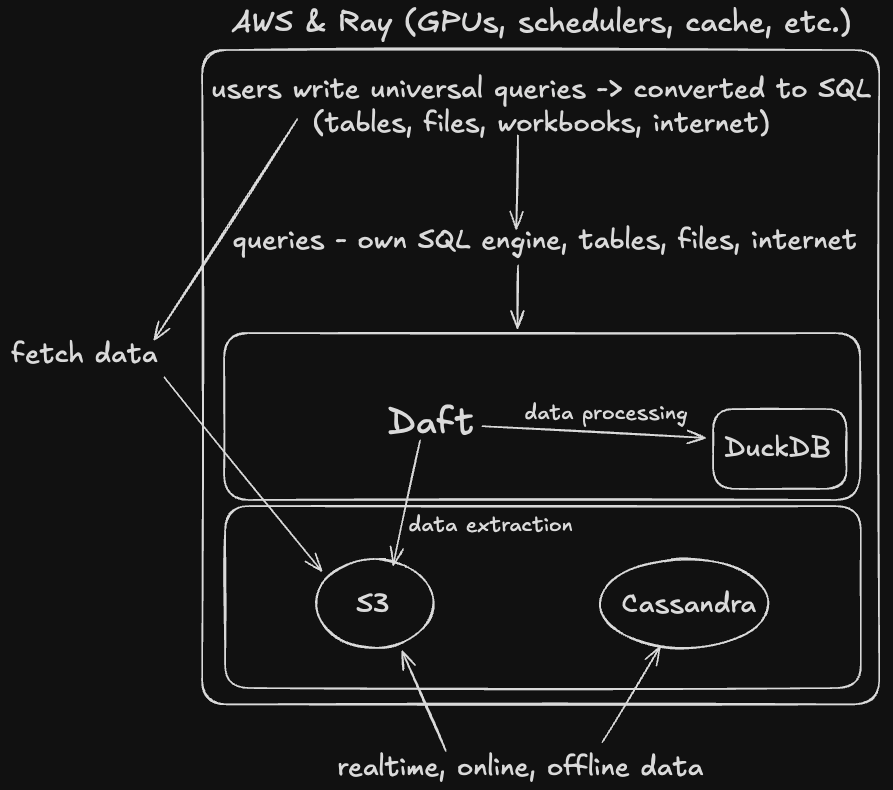
When a user asks Sourcetable to analyze their data:
- The query is parsed by their custom SQL engine
- External data is fetched and written to S3
- Daft reads from S3 and processes the data
- If specific DuckDB plugins are needed (geospatial analysis, specialized connectors), Daft passes the data to DuckDB
- Results flow back through the spreadsheet interface
This "Dyson approach" (as Andy calls it - vacuuming up data in real-time) replaced their original ETL pipeline built on Fivetran. For all but edge cases with severe API rate limits, real-time processing through Daft proved faster and simpler than batch ETL.
"No matter what we put in there, we don't need an ETL pipeline anymore - which is kind of weird if you think about it."
What's Next
Sourcetable is growing at 70% month-over-month and looking to expand into more sophisticated use cases:
Enterprise scale: Preparing for customers who need petabyte-scale processing
More reliable GPU workflows: Simplifying GPU orchestration and reducing infrastructure instability
More real-time for financial use cases: Supporting day traders who need faster data access
In fact, we're covering some of these use cases through our new Daft Cloud platform. You can request a demo here.
References
- Sourcetable - The world's first AI spreadsheet
- Daft - Distributed data engine for Python
- How Sourcetable Built the World's First AI Spreadsheet with Daft (video)

