
Knowledge curation (not search) is the AI big data problem
Google was Information Retrieval. Wikipedia is Knowledge Curation.
by Jay ChiaDo you remember the internet before Wikipedia?
If you were a kid in 2000 and you asked, "Why did the dinosaurs go extinct?", you didn't have one place to go. You had Google. You had Encarta. You had Britannica if your parents were fancy.
So you did what we'd now call agentic search: try a few Google queries, open a few pages, throw out the junk, synthesize an answer and (if you were unusually diligent) write it down for next time.
Wikipedia changed that. Not because it was the best search engine, but because it materialized shared synthesis. It turned an expedition into a single hop. Someone did the work once, and everyone else reused it. Then hundreds of edits made it sharper and more durable. Behold the Wikipedia page on the Cretaceous-Paleogene extinction event!
Wikipedia solved Knowledge Curation for web data. It might be fair to say that it is kind of a world model for public data available on the internet.
However, the non-web variant of this problem over enterprise/personal/work data is still a wide open problem space. And it's one that AI agents keep tripping over.
Wikipedia is just materialized views over unstructured data
Wikipedia isn't a pile of pages. It's a system for doing synthesis asynchronously, then letting everyone reuse it. Do the hard work once, ahead of time, and amortize it across future queries.
In database terms, it's a materialized view!
Interestingly, the uncompressed dump of English Wikipedia is only about 100GB. The information retrieval/search problem for Wikipedia could likely be vibe-coded and turned in as a sophomore year Computer Science college project that runs on your laptop.
However, the amount of synthesis and knowledge curation "inference tokens" that went into building Wikipedia dwarfs the amount of work that's needed to search over it. That is the true cost, and also the true value of Wikipedia.
Google spends compute on indexing to help you find relevant documents. Wikipedia expends a ton of "test-time compute" (raw human brain cycles) to help you reuse curated knowledge.
On private data, AI needs the latter more than the first.
Why agents are smarter on the web than at work
On the public web, the hard part is finding the right stuff (information retrieval). It's a top-k game: needles in a haystack.
And the web, despite the chaos, has a map! Links and citations give you structure. Once you land somewhere decent, you can hop your way into missing context in two or three clicks. "Authority" even has a shape, because the graph gives you one. That's a big part of why web search works and was the initial idea behind Google.
Private data is the inverse.
Your customers/users don't have billions of pages. They have thousands. But these documents are plagued by unwritten context. These key nuggets of information live in what is often called "tribal knowledge". You could put every document from a company's Google Drive into the LLM's context window and still not have a good answer because of the lack of context from "The Room Where It Happens".
This is a problem if you are building AI products that need to work well on knowledge about your users across their Slack, Sharepoint, Notion, Drive, tickets, docs, meeting notes, spreadsheets or even a ~/Downloads folder. A Slack message says "Let's do the usual," or "Ship it." You can retrieve the thread and the doc and five related threads and still not know what "usual" is, or what to actually "ship".
So the core problem on private data isn't search. It's knowledge curation.
The data story so far: from RAG to Agentic Search
When an agent needs knowledge it doesn't have, we give it tools: connectors, RAG, vector search, browsing, "skills". They mostly do the same thing: return raw fragments and ask the model to make sense of them at runtime.
An AI Agent is often compared to a junior hire. But using this workflow with a junior hire would be unreasonable and doesn't set them up for success! You wouldn't ask a new intern to build a Q3 marketing campaign armed only with Slack, Notion, and Salesforce fragments. That's a disaster waiting to happen.
A good intern synthesizes. They don't just retrieve the right context, they build new/necessary context. They ask, "Why the color blue?" "Who is the ICP?" "What are the pitfalls?"
Unfortunately as much as companies try to write things down, these answers often only exist as "tribal knowledge" in someone's head. Raw reasoning traces are the necessary unstructured raw ingredients for reconstructing context behind key decisions or insights.
Similarly, giving agents raw search access just doesn't compound. Especially for private data.
We redo the same understanding. Two people ask adjacent questions. The agent repeats retrieval and synthesis. Same sources, same reasoning, same answer -- freshly recomputed. Real organizational questions will inevitably cluster around certain concepts, but the system doesn't get leverage from that.
Updates arrive as deltas, not updated beliefs. A doc changes. A ticket closes. A policy gets revised. Nothing gets merged into "what we currently know", so correctness becomes a gamble at runtime. Hopefully the agent is able to retrieve both the appropriate base information and the delta. Then hopefully it is able to make the appropriate synthesis of the two! And it has to do this reliably every single time.
Raw text is cheap; meaning is expensive. A snippet can be technically relevant and still misleading without context. That's how agents can be confidently wrong and hallucinate. And context is difficult to find -- it might be found only after many agentic search hops, or perhaps needs to be inferred from many different sources.
Context rots and especially over long agent horizons. Raw corpora are noisy. Tool schemas are noisy. Stuff piles into the context window, lowering the signal to noise ratio. Agents tend to do poorly when running long horizons.
Provenance becomes everyone's problem. If you don't have a layer that tracks where knowledge came from and what it's allowed to be used for, every agent has to reinvent safety, citations, and permissions.
The next frontier for AI Agents: knowledge curation
We're getting better at connecting models to private systems. ChatGPT has added the concept of Apps and Company Knowledge, and Anthropic is pushing hard on MCP servers and Skills. Our agents can now access our data in Notion, Slack, Google Drive and more, but this access to raw data just means the agent can retrieve snippets of facts.
However, we still live in a world not unlike the parable about the blind men and the elephant.
The first blind man put out his hand and touched the side of the elephant. "How smooth! An elephant is like a wall." The second blind man put out his hand and touched the trunk of the elephant. "How round! An elephant is like a snake." (...more blind men imagining the elephant like a spear, tree, fan and rope)
An argument ensued, each blind man thinking his own perception of the elephant was the correct one. The Rajah, awakened by the commotion, called out from the balcony. "The elephant is a big animal," he said. "Each man touched only one part. You must put all the parts together to find out what an elephant is like."
The moat for AI products and teams will be an autonomous, versioned, citable knowledge layer: synthesized context views that stay in sync as the underlying messy raw data changes. If the elephant grows out its tusks, our common understanding of what an elephant is should evolve.
The labs such as OpenAI and Anthropic are both working on this problem. Here is OpenAI's new knowledge functionality, powered by all the investments it has made already into Apps that you can connect to it. This is ChatGPT's latest "Company Knowledge" feature:
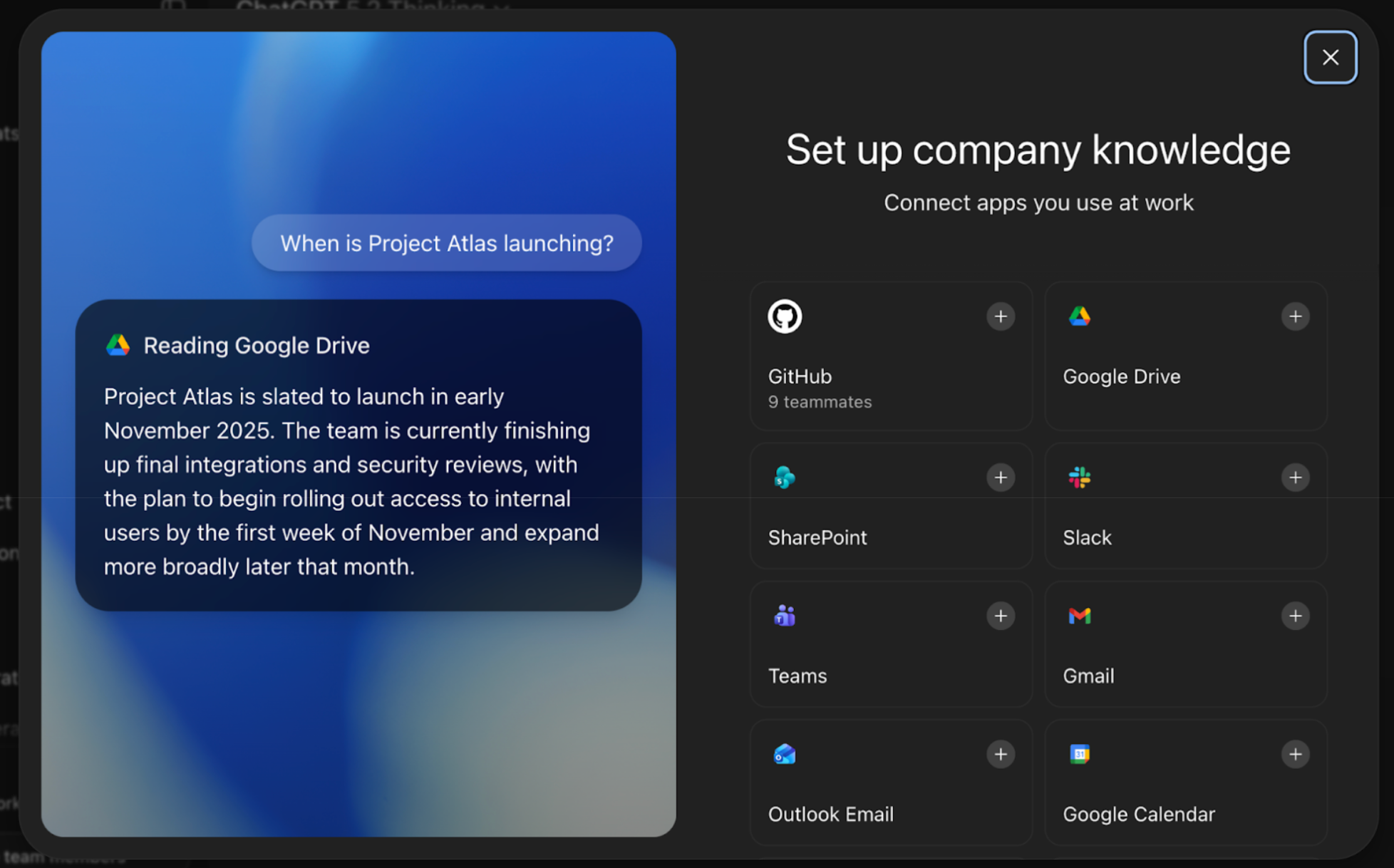
Having access to such a knowledge layer enables applied AI teams to build:
Personalization: have your AI product work well for each individual user or organization
Fresh Knowledge: sync raw data to knowledge continuously as it is created
Less Hallucination: if information isn't available in the knowledge layer, throw an error rather than attempting to extrapolate facts. Reduce hallucination to a classification problem
Cost and time efficiency: tool calls and schemas in your context window costs time and money. Run precomputation to reduce runtime costs. This is "just" indexing for Databases 101.
Provenance and Governance: this can and should be tracked in a dedicated system, just as how Wikipedia has its own contribution history and inter-article reference mechanisms
Memory: agents at runtime should have the ability to persist valuable synthesized information
Knowledge Curation feels like the next moat for AI labs and product teams to compete on (beyond raw model ability). Teams that can do this effectively will be a quantum leap ahead of everyone else in terms of being able to build rich, contextual AI products.
Expert Systems are back in 2026
It turns out that researchers have been dreaming of building such systems early into the dawn of computer science. This class of systems is called Expert Systems and on a high level consists of 2 components: a knowledge base and an inference engine.
In the 1980's such systems were unreasonably expensive to build and maintain -- the inference engine required an expert to manually build out complex rule-based logic that ends up looking a lot like a programming language.
However, the landscape has drastically changed. Large portions of the inference engine are now arguably automatable and tractable using LLM-based transformations today. In other words, Expert Systems/Knowledge-Based Systems are now actually pretty viable to build.
It's an exciting time in data and AI -- not because we need more dashboards or training datasets, but because we finally have the means to build systems that autonomously process unstructured/multimodal data and synthesize knowledge.
We keep treating private data like it's just a pile of documents to be RAG'ed or "hybrid-searched" over. It's not. It's actually a crappy half-baked world model.
The job now is to build the rest.

