
Multimodal Embeddings: Tutorial & Examples
Learn multimodal embedding techniques for cross-modal search, recommendation systems, and content moderation applications.
by Desmond CheongThe term "modality" refers to the form that a data element takes, such as text, an image, audio, video, or a table. Real-world data often does not belong to a single modality but combines multiple modalities; for example, product listings come with images and descriptions, while videos may come with subtitles or transcripts.
Multimodal embeddings help project multimodal information into a shared vector space, enabling the understanding of relationships across modalities and facilitating comparisons and contrasts. This unified representation facilitates interaction with complex real-world data by enabling cross-modal reasoning.
This article explores the concepts behind multimodal embeddings, the frameworks that can be employed, and the typical challenges encountered when working with them.
Summary of key multimodal embeddings concepts
| Concept | Description |
|---|---|
| Multimodal embeddings | Multimodal embeddings help project information from multiple modalities like text, images, audio, video, etc., into a shared vector embedding space so that semantically closer content across modalities can be closer in shared space. |
| Applications of multimodal embeddings | Multimodal embeddings are used in use cases like semantic search, recommendation systems, media content moderation, healthcare diagnostic data processing, and supporting retrieval and ranking components in content generation workflows. |
| Techniques for generating multimodal embeddings | Encoders with contrastive learning, cross-modal transformers, fusion methods, graph neural networks, etc., can be used to generate multimodal embeddings. |
| Challenges in working with multimodal embeddings | Data heterogeneity and the complexities of data ingestion are critical challenges when working with multimodal embeddings. The lack of frameworks that can handle multimodal and relational data uniformly and the engineering overhead associated with them is another challenge. |
| Best practices while dealing with multimodal embeddings | Start with a pretrained model specific to your domain, implement task-specific fine-tuning, evaluate across modalities, and choose the right frameworks and vector databases to handle multimodal embeddings. |
Understanding multimodal embeddings
Embeddings are numerical representations of data that capture the semantic meaning in a way that can be understood by computers. Embeddings enable the mapping of data into a shared vector space so that software systems can examine similarity, identify patterns, and understand relationships between different data elements. For example, words that have a similar meaning are positioned closer together in the shared space.
Multimodal embeddings extend this concept to data belonging to different modalities. Multimodal embeddings represent text, images, audio, video, etc., in a unified space. For example, an image of a chest X-ray and a doctor's note about symptoms of pneumonia can be represented closer in the shared vector space, even though they originated from fundamentally different data types.
Representing data as multimodal embeddings helps you search across modalities without switching tools. For example, one can search images and videos using textual queries if everything is represented in the same vector space. Multimodal embeddings also help in treating heterogeneous data in a uniform manner. This helps simplify system design and downstream models to reason across data types without having specialized pipelines for each data type. Another key benefit is the ability to transfer knowledge from data-rich modalities like text to data-scarce modalities like medical images.
Multimodal embeddings are used in several real-world applications across industry domains:
- Creative workflows: Multimodal embeddings support retrieval, ranking, and alignment in creative workflows, such as finding relevant images from text queries or pairing assets across modalities.
- Recommendation systems: Grouping a large amount of assets (like product information, videos, and images) is important in recommendation systems. Multimodal embeddings help achieve this grouping in an automated manner.
- Media content moderation: Media content often needs to go through several manual reviews to ensure that it is compliant with respect to organizational policies and includes the relevant content. Multimodal embeddings help filter or rank content against natural-language policy definitions.
- Enterprise knowledge and decision support systems: In enterprise settings, multimodal embeddings can support decision-making based on mixed knowledge sources. For example, a customer support manager can make decisions regarding chat screenshots, audio transcripts, etc., without actually reading through them.
Techniques for creating multimodal embeddings
A variety of techniques are used to generate multimodal embeddings, with varying trade-offs related to complexity and deployment constraints. Some of the widely used approaches are described below.
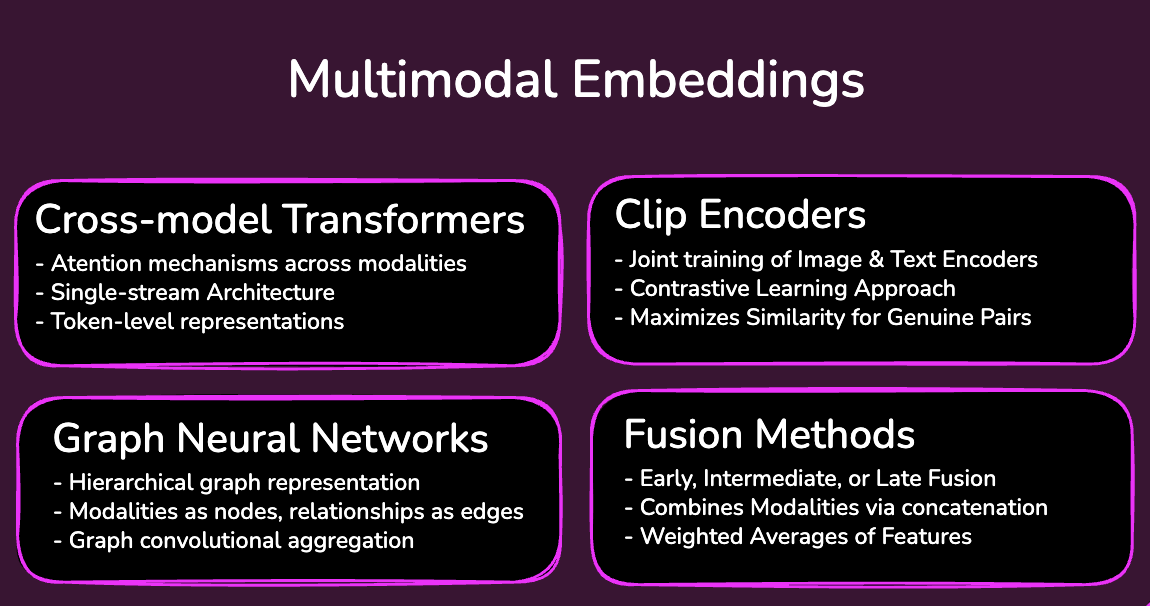
Encoders with Contrastive Language-Image Pretraining (CLIP)
CLIP involves joint training of an image encoder and a text encoder and relies on large-scale paired image-text data and dual encoders trained jointly with a contrastive objective. Fundamentally, CLIP works by learning to predict which image-text pairings within a batch are actually a match. It does this by building an N x N similarity matrix for a batch of N paired image-text examples, increasing similarity for the N matched pairs and decreasing it for the N2 - N mismatched pairs. These similarity scores are used to create a symmetric cross-entropy loss function.
Cross-modal transformers
These are specialized neural networks that use attention mechanisms to learn the relationships between two data types. They allow one modality to attend to another and generate dynamic weights for features from different sources.
Cross-modal transformer architectures vary. Some use separate modality-specific streams that exchange information through cross-attention, while others use a unified single-stream architecture over multimodal tokens. These models often operate on token-level representations and can be more expensive than dual-encoder approaches like CLIP.
Fusion methods
Fusion methods involve combining modalities from different data sources through concatenation, weighted averages, etc. There are three primary fusion strategies:
- Early fusion: The data itself is concatenated before encoding using a single model.
- Intermediate fusion: Different data types are encoded using their respective encoders to extract features, and the features are combined using techniques like concatenation or a weighted average. A downstream network then further processes the combined encoding.
- Late fusion: The combination happens at the final output level and not at the feature level.
Graph neural networks
Graph neural networks can represent multimodal data as graphs, where nodes may correspond to entities, image regions, document sections, clips, or modality-specific components, and edges capture relationships among them. They then use graph convolutional networks to aggregate features from neighboring nodes to generate a joint representation.
Challenges in dealing with multimodal embeddings
While multimodal data has several benefits over single-modal data, dealing with multimodal data is inherently complex. Some of the key challenges in dealing with multimodal data are described below.
Ingestion complexity
Multimodal data is heterogeneous and contains several data types with different scales and statistical properties. For example, text is tokenized and discrete, while audio and video are continuous temporal signals that often require fine-grained time-based modeling. Ingesting multimodal data in a shared space without losing information is a big challenge.
Resource and performance constraints
Generating multimodal embeddings can be resource-intensive, especially during model training or when processing large image, audio, or video corpora. Inference cost varies by architecture: dual-encoder retrieval systems can precompute embeddings offline, while joint cross-modal models may require more expensive token-level computation at query time. GPU memory, model size, input resolution, and batch size all matter greatly.
Framework support
End-to-end multimodal pipelines often span ingestion, preprocessing, embedding, storage, and retrieval, and many teams still compose multiple tools to cover that lifecycle. This can increase engineering overhead, especially when structured and unstructured data need to be handled together. There are some frameworks, like Daft, that handle this problem gracefully with a unified mechanism to handle multimodal data.
Scalability
Processing multimodal data typically requires significant processing time and bandwidth. Processing such data generally has two aspects, the first one being cleaning, transforming, and indexing data in an amenable format, and the second being generating embeddings and running inference using embeddings for application-specific logic. These two aspects differ in terms of the scalability requirements of the processor and storage. Frameworks in this space are disjointed ones with varying levels of abstraction and totally different scaling configurations. Scaling the full multimodal pipeline can be operationally complex because preprocessing, embedding generation, storage, and retrieval often have different compute and latency requirements. Frameworks like Daft can solve this to an extent using unified processing engines.
Working with multimodal embeddings
Having now looked at the complexities of working with multimodal data, let's see how to work with it. For this tutorial, we will use Daft, a unified AI pipeline framework that can convert raw multimodal data into vectors. We will use CLIP for generating embeddings. The code will generate embeddings for a set of images and store them in memory and then search the images using a text query and retrieve the images similar to the query. In this example we use a custom CLIP-based embedder for both images and text so both modalities land in the same embedding space for cross-modal retrieval.
Note: The complete code for the following example is available in this Google Colab Notebook.
- Install the dependencies with the following command.
!pip install daft transformers pillow torch- Start creating a script by adding the necessary import statements.
from __future__ import annotations
import glob
import os
from typing import List, Tuple
import numpy as np
import daft
from daft import col
from daft.functions import cosine_distance
IMAGE_EMBED_DIM = 512- Create utility functions to load images from a folder and generate their paths.
def find_images(root: str) -> List[str]:
exts = ["*.jpg", "*.jpeg", "*.png", "*.bmp", "*.gif", "*.webp"]
paths = []
for ext in exts:
paths.extend(glob.glob(os.path.join(root, "**", ext), recursive=True))
return sorted(set(paths))- Create a CLIPEmbedder class, which has some utility functions to load CLIP and generate embeddings for text and images.
@daft.cls(max_concurrency=1, use_process=True)
class CLIPEmbedder:
def __init__(self, model_id: str = "openai/clip-vit-base-patch32"):
import torch
from transformers import CLIPModel, CLIPProcessor
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.processor = CLIPProcessor.from_pretrained(model_id)
self.model = CLIPModel.from_pretrained(model_id, use_safetensors=True).to(self.device).eval()
@daft.method.batch(
return_dtype=daft.DataType.embedding(daft.DataType.float32(), IMAGE_EMBED_DIM),
batch_size=16,
)
def embed_image(self, paths):
import numpy as np
import torch
from PIL import Image
image_paths = paths.to_pylist()
images = [Image.open(path).convert("RGB") for path in image_paths]
inputs = self.processor(images=images, return_tensors="pt", padding=True)
inputs = {k: v.to(self.device) for k, v in inputs.items()}
with torch.inference_mode():
features = self.model.get_image_features(**inputs)
features = torch.nn.functional.normalize(features, p=2, dim=-1)
return features.detach().cpu().numpy().astype(np.float32)
def encode_text(self, text: str) -> list[float]:
import numpy as np
import torch
inputs = self.processor(text=[text], return_tensors="pt", padding=True, truncation=True)
inputs = {k: v.to(self.device) for k, v in inputs.items()}
with torch.inference_mode():
features = self.model.get_text_features(**inputs)
features = torch.nn.functional.normalize(features, p=2, dim=-1)
return features[0].detach().cpu().numpy().astype(np.float32).tolist()- Create the main function using all the utility functions defined so far. The main function will use the CLIPEmbedder class and the embedding functions defined in it to generate embeddings. Finally, it will take the text query, embed it, and use it to search the image embeddings.
def main():
images_dir = "/content/images"
query = "a red sports car"
topk = 5
image_paths = find_images(images_dir)
if not image_paths:
raise SystemExit(f"No images found under: {images_dir}")
embedder = CLIPEmbedder()
embedding_dtype = daft.DataType.embedding(daft.DataType.float32(), IMAGE_EMBED_DIM)
images_df = (
daft.from_pydict({"path": image_paths})
.with_column("embedding", embedder.embed_image(col("path")))
)
query_df = (
daft.from_pydict({"query": [query], "query_embedding": [embedder.encode_text(query)]})
.with_column("query_embedding", col("query_embedding").cast(embedding_dtype))
)
results = (
query_df.join(images_df, how="cross")
.with_column("distance", cosine_distance(col("query_embedding"), col("embedding")))
.sort("distance")
.limit(topk)
.select("path", "distance")
)
print(f"Top {topk} matches for query: {query!r}")
for row in results.to_pylist():
print(f"{row['distance']:.4f} {row['path']}")
if __name__ == "__main__":
main()- To run the code, we will need an image dataset. The Kaggle car image data set is a good example that can be used. Once you execute the code with the search query
red sports car, the model will return the highest-scoring matches from the dataset. In a well-labeled car dataset, the top results should usually be visually similar to the query, though the exact ranking depends on the dataset, preprocessing, and model behavior.

Best practices while working with multimodal embeddings
Implementing a production system that deals with multimodal data requires significant engineering effort and paying attention to design considerations. Some of the best practices that can help build a robust system are described below.
Start with a pretrained model for your specific domain
Multimodal embedding models are hard to design and require significant engineering and data science expertise. Fine-tuning a pretrained model is often more practical than training a multimodal model from scratch once you have shortlisted a model that fits the use case. While general models like CLIP work for a variety of use cases, in more involved problems, one may need to undertake task-specific fine-tuning. For example, fine-tuning for text-based search is very different from that needed for generating images from text.
Evaluate across modalities
Before selecting a model, systematically evaluate the quality of the embeddings generated through the model. This evaluation must be conducted across modalities using a well-defined, use-case-specific test. Cross-modal retrieval metrics like recall@K can be used to evaluate the results on the test set.
Maintain metadata
Maintaining metadata about the model architecture and the lineage of various models used in the pipeline is important in AI/ML projects where a lot of experimentation and A/B testing happens. Information about the encoders used for various modalities must be captured, which helps you systematically evaluate various pipeline configurations and predictably switch across various configurations.
Optimize chunking strategies for effective data retrieval
While dealing with large or heterogeneous assets, storing a single embedding for the entire asset may reduce retrieval quality, so teams often chunk content into smaller units and store those separately. For example, while dealing with a large document with images and text, one has to chunk the document into manageable blocks and store them separately. A side effect of this is the loss of context of the whole document because of fragmented storage: An image belonging to a document can end up in a different chunk and text in another chunk. This can be solved to an extent by using chunking strategies like overlapping or semantic chunking.
Profile the entire pipeline
ML pipelines involving multimodal data often take a long time to run, and this is true for both generation and retrieval workflows. Optimizing such pipelines for minimal latency is complex because several moving parts are involved. Profiling the complete pipeline to understand the latency bottlenecks is a good practice while implementing multimodal applications.
Last thoughts
Multimodal data is useful in several applications, like creative workflows, recommendation systems, content moderation, and even enterprise decision systems. While they offer rich information compared to single-modal data, dealing with them is inherently complex. Complexities related to ingestion, scalability, resource constraints, and a lack of good frameworks hinder progress when dealing with multimodal data. A unified framework like Daft that can natively work with multimodal data while abstracting away the complexities of infrastructure management can help make this journey easier.

