
Benchmarks for Multimodal AI: Spark, Ray Data, and Daft
Multimodal AI workloads break traditional data engines. Daft ran 2-7x faster than Ray Data and 4-18x faster than Spark while finishing jobs reliably across audio, video, document, and image workloads.
by Colin HoTL;DR
Multimodal AI workloads break traditional data engines. They need to embed documents, classify images, and transcribe audio, not just run aggregations and joins. These multimodal workloads are tough: memory usage balloons mid-pipeline, processing requires both CPU and GPU, and a single machine can't handle the data volume.
Daft is designed to handle these workloads. We benchmarked it across large scale audio, video, document, and image workloads against Spark and Ray Data. Daft ran 2-7x faster than Ray Data and 4-18x faster than Spark, while finishing jobs reliably. The full benchmark code is open-sourced here.
Why Multimodal Benchmarks Matter
Benchmarks aren't new. Engineers already rely on them to compare systems. But most of the standard ones, like TPC-H for SQL or MLPerf for training, were designed around very different workloads. TPC-H was meant for business oriented queries on tabular data, involving aggregations and joins, while MLPerf focuses on training and inference, less so the data processing that comes before. They don't capture what happens when you need to get from raw PDFs and videos, into both CPUs and GPUs.
That's why multimodal benchmarks matter. Without them, it's impossible to tell whether a data engine will hold up once "rows" aren't integers or strings, but multi-megabyte binaries that stress I/O, CPU, and GPU all at once.

We see the limitations clearly in today's tools. Spark has been optimized for SQL-style analytics on tabular data, and it struggles to keep GPUs fully utilized. Ray Data can stream data better, but can spill excessively to disk, and its lack of sophisticated query planner still leaves too much tuning for the user. The problems are familiar: out-of-memory crashes, idle GPUs, and endless hand-tuning of partition sizes or executor memory.
Daft was designed differently, with multimodal data (audio, video, images, text, embeddings) as first-class citizens. With Flotilla, our new distributed engine, those design choices extend across the cluster. The goal isn't just to run pipelines faster, but to make them reliable at scale, without engineers spending days tweaking configurations just to get a job to complete.
This post goes behind the scenes of how these systems perform in practice. We'll share head-to-head benchmarks of Daft, Ray Data, and Spark on real multimodal workloads collected from users in production, explain why the architectural differences matter, and show where Daft's streaming execution model makes the biggest impact. All code and logs are published, so you can reproduce the results yourself.
Benchmark Setup
To maintain a fair comparison, we ran Daft, Ray Data, and Spark on identical AWS clusters and workloads, which reflect real-world multimodal pipelines.
Cluster Configuration
- 8 AWS g6.xlarge instances, each with:
- 1 NVIDIA L4 GPU, 24 GB GPU memory
- 4 vCPUs, 16 GB memory
- 100 GB EBS volume
- All instances are colocated in the same availability zone
Software Versions
- Daft 0.6.2
- Ray Data 2.49.2
- Spark EMR 7.10.0
Workloads Tested
-
Audio transcription — 113,800 audio files from Common Voice 17 transcribed using OpenAI Whisper-tiny. The audio files are inlined as bytes in parquet files in S3 (audio can be small enough for this). Processing steps include resampling, feature extraction, transcription, and writing results back to S3 in parquet.
-
Document embedding — 10,000 PDFs from Common Crawl embedded with all-MiniLM-L6-v2. PDFs are stored as blobs in object store, with parquet files containing metadata and image URIs. The PDFs are downloaded onto the workers, text is extracted, chunked, embedded, and written back to parquet in S3.
-
Image classification — 803,580 images from ImageNet classified using ResNet18. Images are stored as blobs in object store, with parquet files containing metadata and image URIs. The images are downloaded onto the workers, decoded to RGB, resized, normalized, and classified. The image URIs and labels are written as parquet files in s3.
-
Video object detection — 1,000 videos from Hollywood2 analyzed with YOLO11n. The videos are stored as blobs in S3, which are then downloaded and decoded into frame. Each frame is passed through the YOLO11n model, and object features are produced. The bounding boxes are then used to crop the frame to extract the object. The cropped object images are then written to S3, inlined in parquet files.
Each workload is characteristic of a real production situation. Large blobs are stored separately from metadata in object storage, while smaller ones like audio or small images can be inlined in parquet files. They share similar characteristics, in that they are I/O heavy (large binaries), CPU heavy (decode/parse), and GPU heavy (inference).
Reproducibility
All benchmark scripts and raw logs are open-sourced. Anyone can rerun these experiments on AWS with the same setup (links at the end).
Results
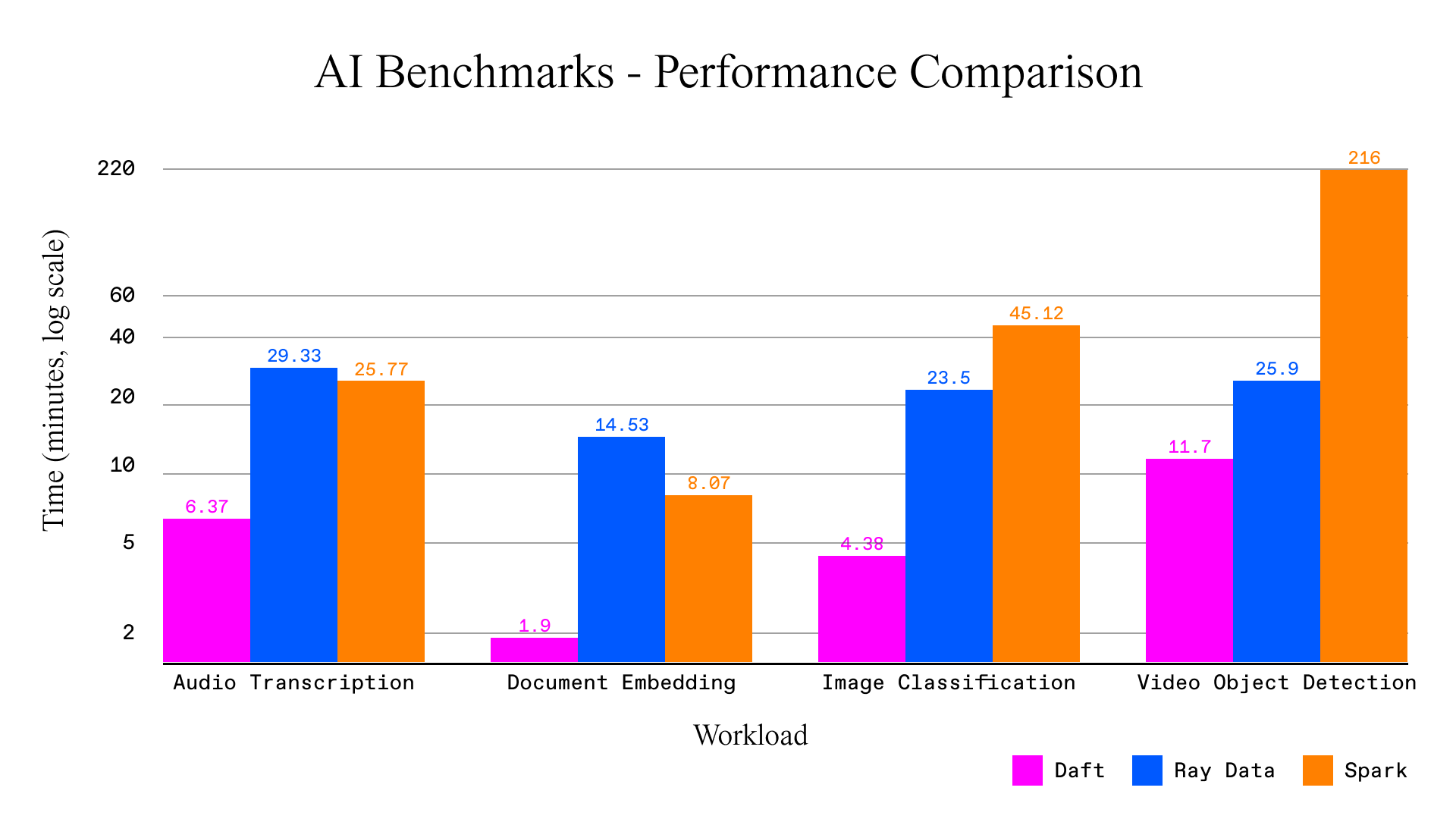
| Daft | Ray Data | EMR Spark | |
|---|---|---|---|
| Audio Transcription | 6m 22s | 29m 20s (4.6x slower) | 25m 46s (4.0x slower) |
| Document Embedding | 1m 54s | 14m 32s (7.6x slower) | 8m 4s (4.2x slower) |
| Image Classification | 4m 23s | 23m 30s (5.4x slower) | 45m 7s (10.3x slower) |
| Video Object Detection | 11m 46s | 25m 54s (2.2x slower) | 3h 36m (18.4x slower) |
(lower is better — full code and logs are published for reproducibility)
On the lighter workloads (audio, documents), Daft's performance was 4-8x higher, but the gap widens on heavier pipelines, where Spark took more than 45 minutes to classify 800k images that Daft finished in four, and over three and a half hours on the video detection benchmark, where Daft in under twelve minutes.
Observations
-
Daft finished every run without task failures. The only parameter that needed to be tuned was the batch size of the UDF when running models. This was enough to keep memory usage stable throughout the workloads.
-
Ray Data was generally successful, but prone to OOMs unless batch sizes were configured correctly, and often they had to be smaller than optimal. This is evident in the document embedding pipeline, where the batch size for embedding was configured to be only 10 rows. We initially tried with higher, e.g. 100, but it was causing too many failures. For the audio transcription pipeline, we set the batch size to 64, which still caused some failures but the job was still able to complete.

- Spark was extremely susceptible to OOMs with the default configurations. For instance, we had to set
spark.executor.cores=1for all workloads except image classification. This controls how many cores are assigned per executor, and effectively controls how many concurrent tasks per executor. Additionally, we also had to tune batch sizes viaspark.sql.execution.arrow.maxRecordsPerBatch, to match the batch sizes for Daft and Ray Data. The problem with Spark is that this is a global config, which means it affects all UDFs, some of which could benefit from larger batch sizes. Without these two methods of tuning, we found that Spark was susceptible to OOMs.

One of the most important observations from this benchmarking exercise was that reliability trumps performance in production. It doesn't matter how fast something is if you can't even get a workload to run, or if it runs successfully only half the time.
Why Spark and Ray Data Struggle
Benchmarks tell us what happened. To understand why, we need to look at how each engine handles the three fundamental challenges of multimodal pipelines: exploding data volumes, keeping hardware busy, and giving developers an API they can actually use.
1. Managing Large-Scale Data Volumes
Multimodal data often grows mid-pipeline: a compressed image like a JPEG inflates 20x in memory once decoded, and a single video file can be decoded into thousands of frames each being megabytes.
-
Spark fuses operations into a single task, and executes these operations sequentially on partitions of data. In the image classification workload, this means that for a ~100k row partition containing JPGs that need to be classified, Spark will decode all 100k images into tensors before feeding them into the GPU for inference. This was a recipe for memory blowups, and to survive we had to configure the global batch size via
spark.sql.execution.arrow.maxRecordsPerBatch -
Ray Data similarly fuses sequential operations into the same task and executes them sequentially. Without manual tuning of block sizes, you'll hit the same OOMs. Unlike Spark though, you have a way to avoid this by using classes in
map/map_batchesinstead of functions, which will instead add a boundary between operations by materializing intermediates in its object store (which is used to transfer objects across different processes and different nodes). However, this adds serialization and memory copy overhead. Not to mention that Ray's object store is by default only 30% of the machines, and this limitation can lead to excessive disk spilling. -
Daft takes a different approach. Unlike Spark or Ray Data, Daft doesn't need to stage entire partitions in memory or spill them out to disk between operators. Daft's Swordfish execution engine uses a streaming execution model where data is always "in flight": batches flow through the pipeline as soon as they are ready. For a partition of a 100k images, the first 1000 can be fed into model inference, while the next 1000 are being downloaded or decoded. The entire partition never has to be fully materialized in an intermediate buffer. A key part of this model is backpressure. If GPU inference becomes the bottleneck, the upstream steps automatically slow down so memory usage remains bounded. The pipeline also adapts dynamically: Daft shrinks batch sizes on memory-heavy ops like
url_downloadorimage_decode, keeping throughput high without ballooning memory usage.
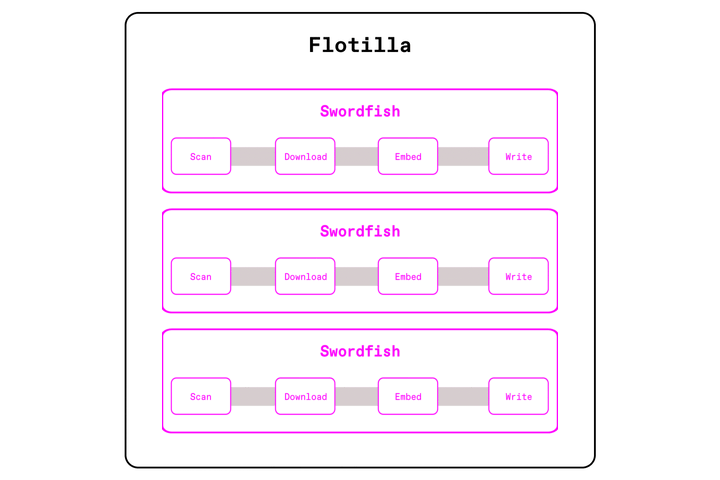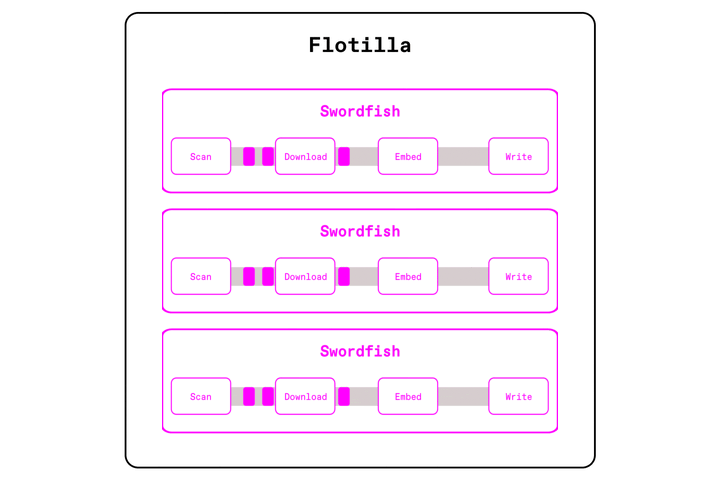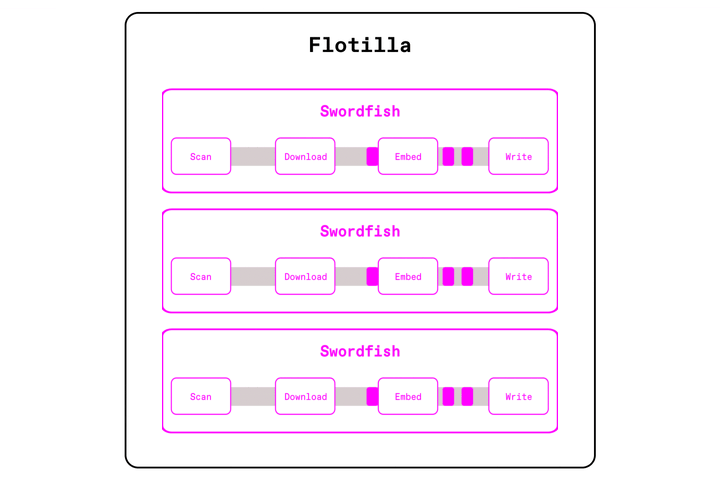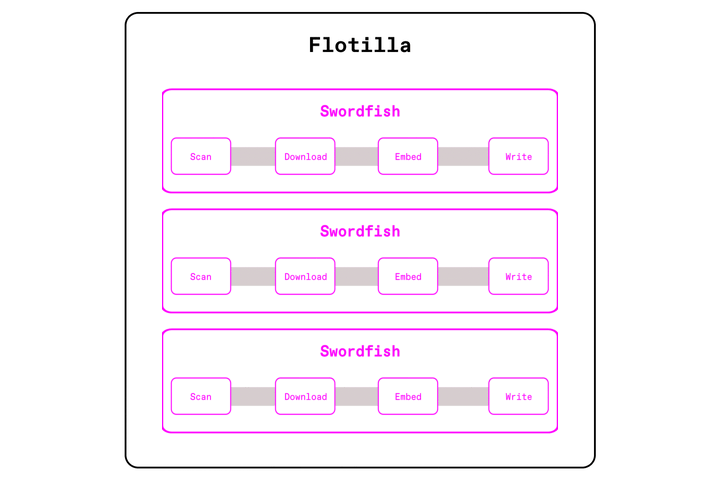
Why Daft wins: Memory inflations are controlled within the engine, user intervention to control batch or partition sizes is minimal.
2. Efficient Use of Hardware Resources
Multimodal pipelines stress CPU, GPU, and network simultaneously. The challenge is keeping all three busy together to maximise utilization and throughput.
-
Spark maps a pipeline running on a partition to a single task, which by default runs on a single core. If you're running GPU nodes, it also assumes one task per GPU. This means that only one task is running on an executor at a time, leaving many cores idle, significantly lowering throughput. However, if you configure Spark to use more than one core per task (via
spark.executor.cores), now you get multiple tasks fighting for the GPU (assuming you have one GPU per node). This poses a risk for running out of memory on GPU memory. -
Ray Data can separate operations that require different resource requirements into separate tasks, such as a CPU pre-processing step and a GPU inference step. We did this by specifying that the model inference step required
num_gpus=1and that we hadconcurrency=num_nodesnumber of gpu nodes. Ray Data enables this separation by materializing data in its object store, such that different processes can perform the separate operations. However, for operations that are significantly I/O bound, such as downloads of large videos, Ray Data by default reserves a CPU core for this work, starving CPU bound work from using it. While it is possible to provide fractional cpu requests, this involves a lot of guess work, which can be an overhead to engineering time. -
Daft pipelines everything inside a single Swordfish worker, which has control over all resources of the machine. Data asynchronously streams from cloud storage, into the CPUs to run pre-processing steps, then into GPU memory for inference, and back out for the results to be uploaded. CPUs, GPUs, and the network stay saturated together for optimal throughput. The design decision to make a worker control the entire machine was crucial, as Daft can properly pipeline heterogeneous operations without leaving resources idle. For instance, Daft could asynchronously download videos without blocking CPU cores for frame extraction, resizing, and other preprocessing steps.

Why Daft wins: Data is streamed through network, CPU, and GPU in a continuous stream, enabling maximum resource utilization.
3. Flexible and Python-native APIs
Performance and scalability isn't enough. Multimodal pipelines involve a series of complex steps, involving reading and writing from different data sources, transforming data, and running models over data. Additionally, being able to express transformations in Python code is especially important for multimodal and AI workloads.
-
Spark has an expressive SQL and DataFrame APIs. It has a sophisticated query optimizer so you don't need to think about where to inject filters, or when to prune columns. However, its Python and Pandas UDF experience lacks flexibility, it is not possible to specify resource requirements or batch sizes on specific UDF, only globally, via
spark.sql.execution.arrow.maxRecordsPerBatch. Tuning and optimizing can also be difficult, with thespark.confcontaining hundreds of fields that may or may not be useful for the particular workloads. -
Ray Data exposes a Dataset API with more lower level operators like
mapormap_batches, similar to Spark's RDDs. Almost all transformations have to be done via custom python functions, which can add a lot of developer overhead. Furthermore, Ray Data's planner is not as sophisticated as Daft's or Spark's, which means the developer needs to pay special attention to make sure that their order of operations, column selection, datatype selection, are all optimal. This can cause a lot of burden on the developer, especially when you have multiple processing steps or columns. Lastly, Ray Data also does not do schema validation, which means simply checking the schema of the dataset requires executing a sample of the query, costing time and money. -
Daft combines the best of both worlds, a declarative DataFrame/SQL APIs with schema validation and query optimizer. Users can define their queries declaratively without worrying about performance, check the schema of their data instantly, and benefit from a myriad of built in multimodal operators (image decode, embed, cosine similarity, text normalization, etc.) that are tightly optimized and integrated within the engine. Furthermore, if needed, Daft's UDFs have the flexibility to be individually tuned, with parameters like batch size, concurrency, and resource requests.
df = daft.read_parquet(INPUT_PATH)
# Download images and decode them using Daft's native expressions
df = df.with_column(
"decoded_image",
df["image_url"].url.download().image.decode(mode=daft.ImageMode.RGB),
)
# Apply the transform and model to the decoded images using UDFs
df = df.with_column(
"norm_image",
df["decoded_image"].apply(
func=lambda image: transform(image),
return_dtype=daft.DataType.tensor(dtype=daft.DataType.float32(), shape=IMAGE_DIM),
),
)
df = df.with_column("label", ResNetModel(col("norm_image")))
# Select the image URL and label columns and write to Parquet
df = df.select("image_url", "label")
df.write_parquet(OUTPUT_PATH)Example image classification workload with Daft
Why Daft wins: Declarative ergonomics plus multimodal-native operators help developers get started quicker, and makes maintenance easier.
What This Means for You
The increasingly dominant workloads in AI are multimodal: documents, images, audio, and video. Spark was built for SQL analytics and can't keep GPUs busy. Ray Data streams better, but materializes intermediates and leaves optimization to the user. Daft was engineered for multimodal AI: adaptive batch sizing, end-to-end pipelining, and declarative APIs with multimodal-native operators.
Across audio, documents, images, and video, Daft wasn't just faster — it was the only engine that finished jobs reliably without endless manual tuning. For engineers scaling multimodal pipelines, reliability matters more than any headline speedup.
Try it out yourself
All code and logs are open-sourced. You can rerun the benchmarks on AWS and compare against your stack:
Already running multimodal data workloads with Daft? Join our community slack to tell us your story, get updates, and join in on the fun!

