
Introducing Flotilla: Simplifying Multimodal Data Processing at Scale
Flotilla, Daft's new distributed engine, processes terabytes of multimodal data in a single query up to 18x faster than Spark and Ray Data, while running efficiently, reliably, and without manual tuning.
by Colin HoTL;DR
We redesigned our distributed execution engine to improve the scalability and performance of multimodal data workloads. Flotilla, Daft's new distributed engine, processes terabytes of multimodal data in a single query up to 18x faster than Spark and Ray Data, while running efficiently, reliably, and without manual tuning.
The Pain of Scaling Multimodal Data
Imagine you're tasked with ingesting PDFs for a search and retrieval application. Each one needs to be downloaded, parsed, embedded, and stored in a vector database for semantic search.
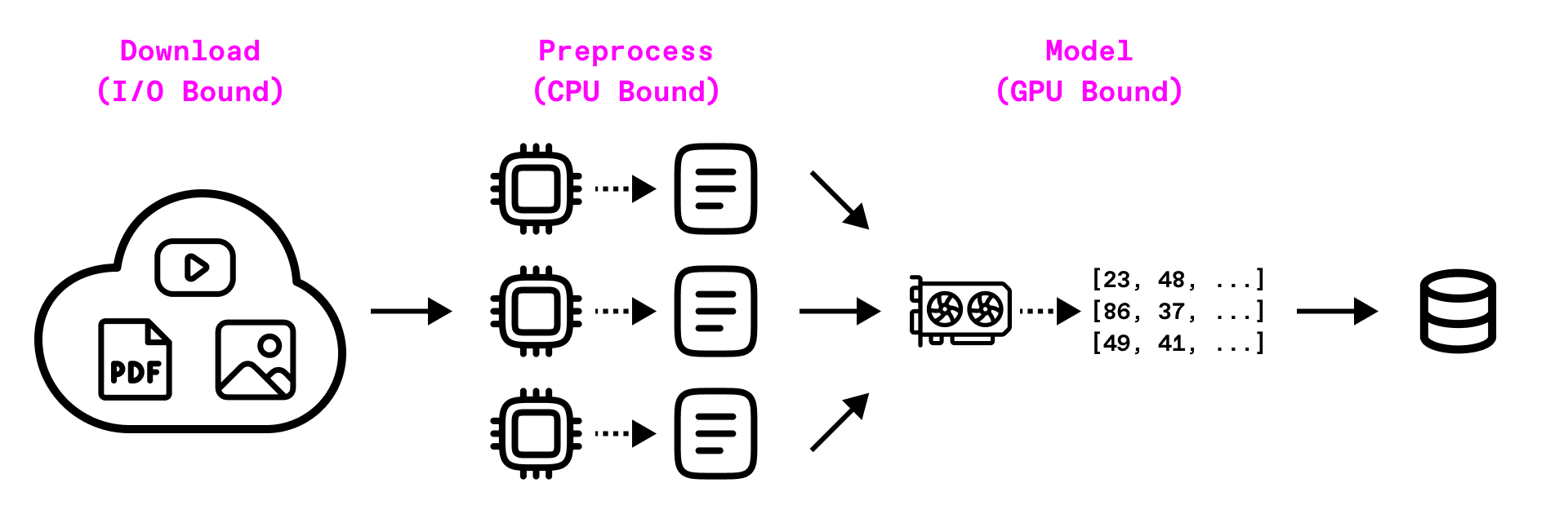
On a small dataset, you might get away with running this on a single machine. But at real-world scale, hundreds of thousands or millions of PDFs, the limits start to show:
-
You need multiple GPUs. Embedding text at scale can't be done fast enough on one accelerator; the workload has to be spread across many.
-
A single machine hits I/O ceilings. Network and disk throughput quickly become bottlenecks when you're downloading terabytes of PDFs and streaming large binary blobs.
-
Bigger boxes don't solve everything. High-memory, multi-GPU machines are expensive and often scarce in the cloud. Scaling out with a cluster of smaller, cheaper nodes is usually more practical.
That's why you need distributed execution. But existing tools weren't built with multimodal data in mind.
Why existing data tools aren't good enough
Historically, distributed data processing has meant using an engine like Spark. Spark was designed for workloads like large-scale analytical workloads involving aggregations or joins, where you have millions of rows that get filtered or reduced as they progress through a query. Multimodal data is different: individual rows can be gigabytes to begin with, and often get larger as they progress through the pipelines.
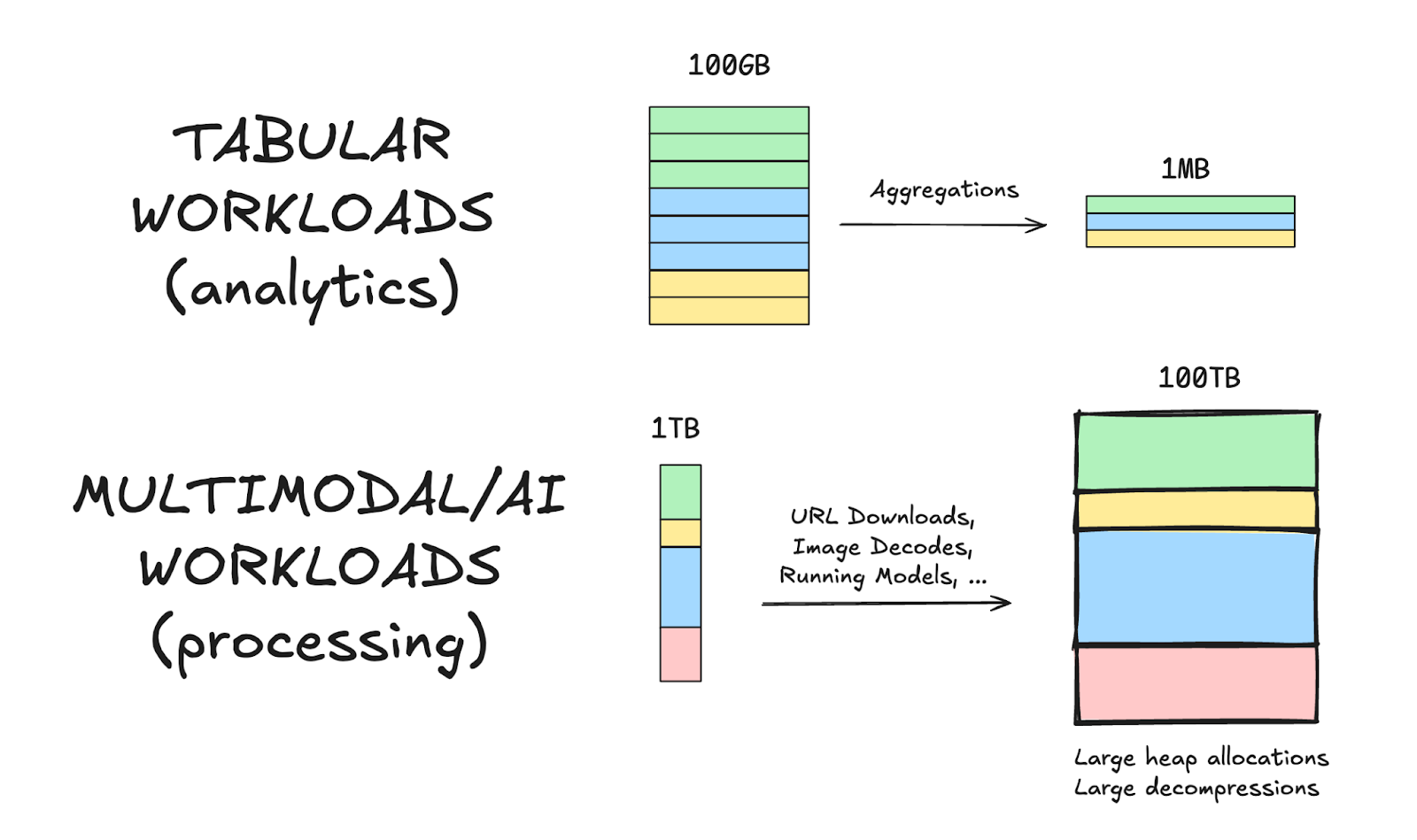
To execute these operations on a cluster, Spark splits the input data into partitions, and distributes them to workers that run each operation sequentially on a single core. In fact, this is the same architecture that Daft's previous engine had as well.
This means that for each partition, which could contain a thousand rows of urls to PDFs, it will download all the PDFs, then parse the text, then embed them, and finally write them to storage. Without proper partition sizing, you can easily OOM without even finishing all the downloads. Furthermore, this is a recipe for poor hardware utilization. CPUs are waiting idle during the downloads, and GPUs can't even start until parsing is complete.
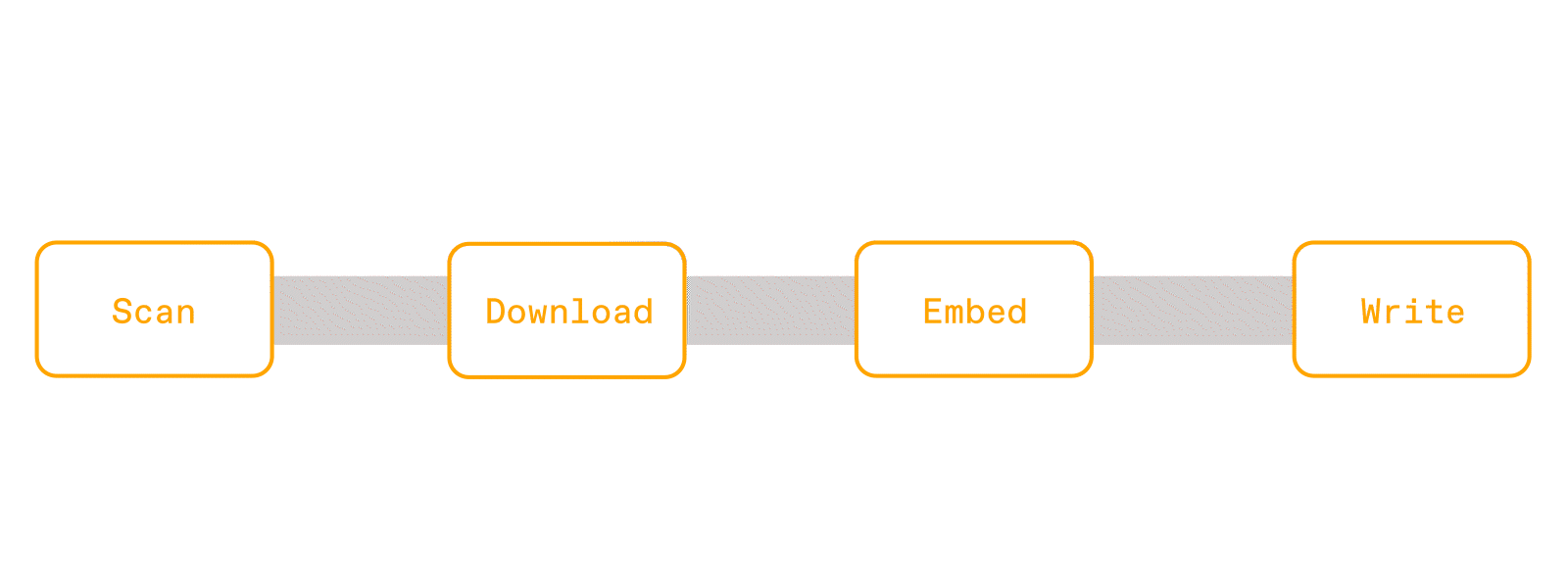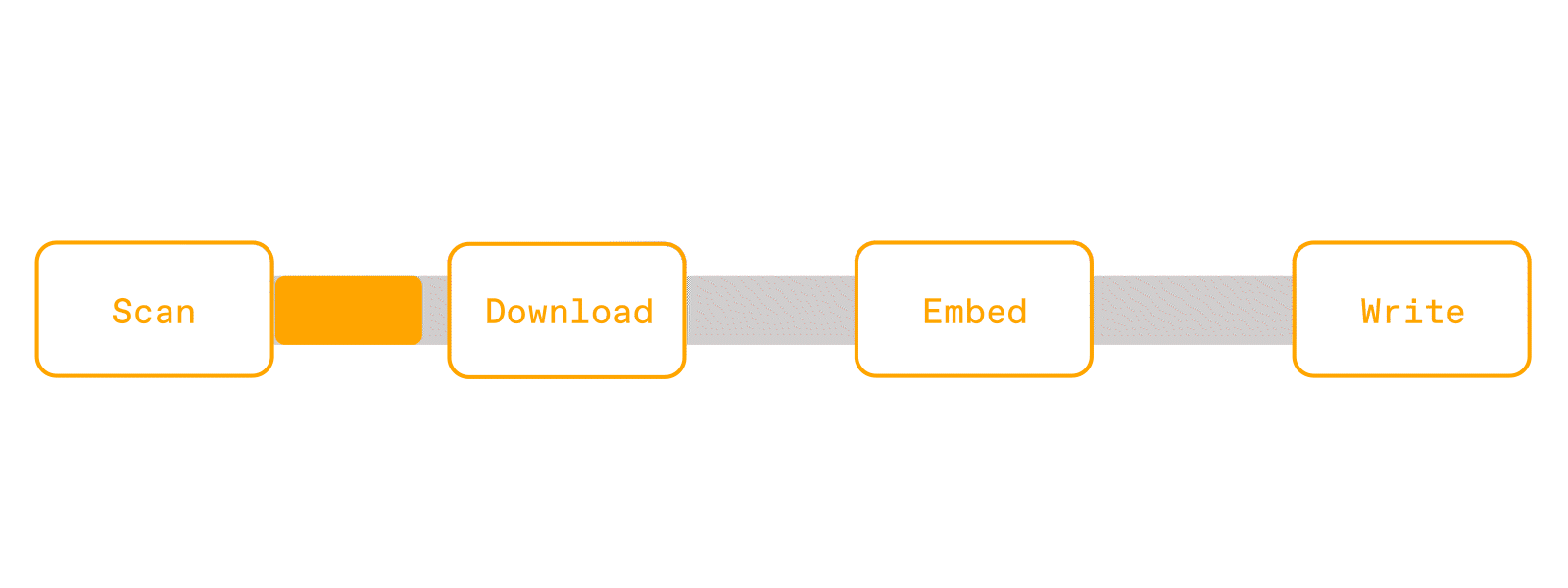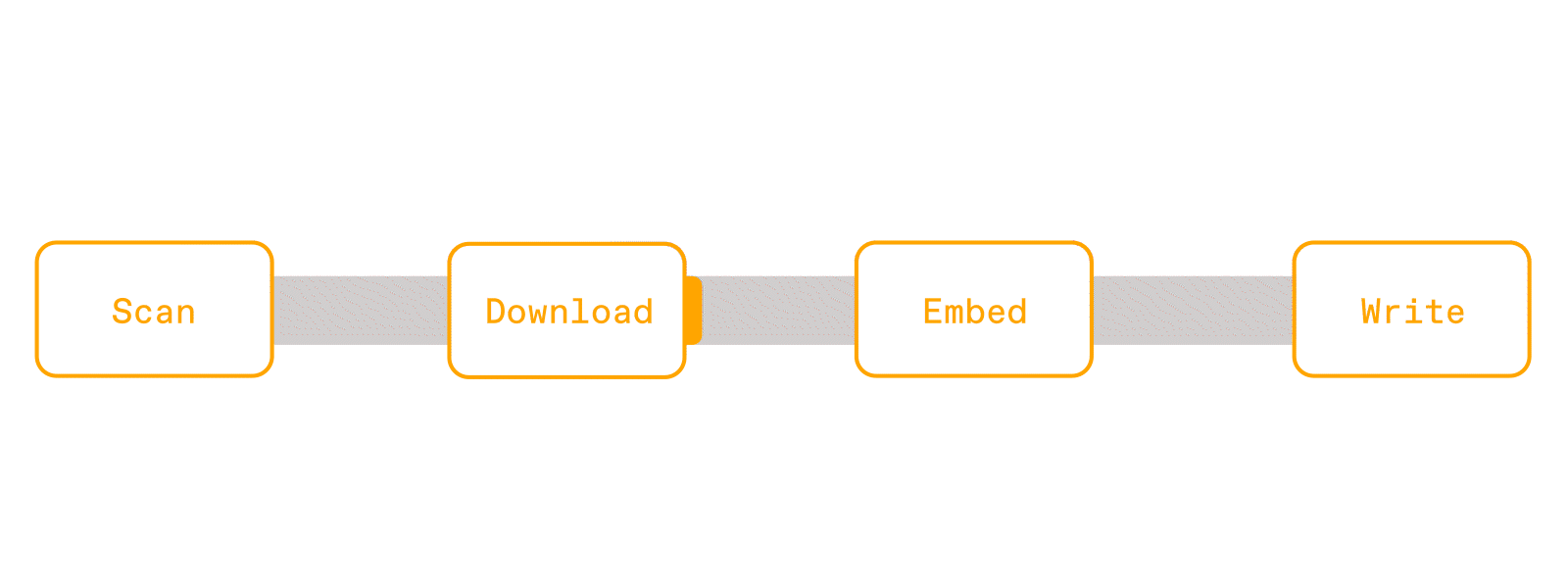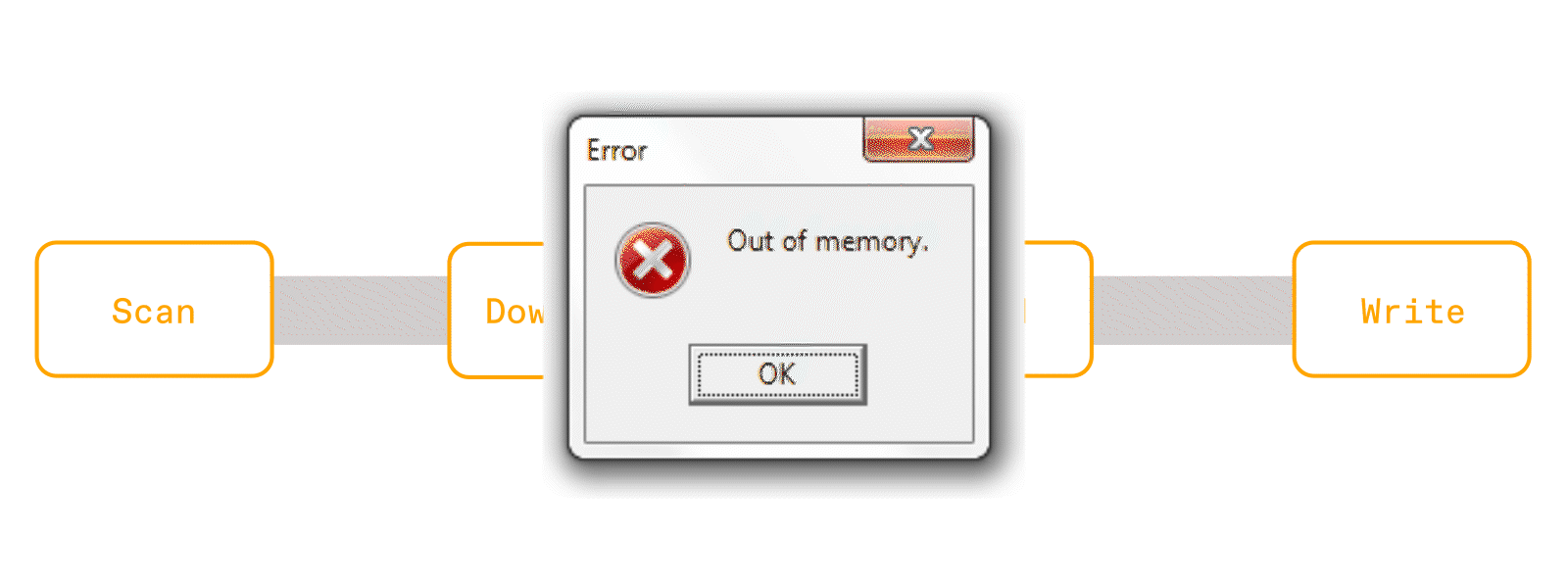
But people still opt to use Spark because of its familiar API and mature ecosystem. People like using Dataframes and SQL because it's declarative, and the query optimizer takes care of making things efficient. If a query is slow or failing, users can debug because Spark has built in progress, metrics, and logs into the dashboard.
We wanted an engine that lets you express multimodal workloads declaratively, but also understands the quirks of multimodal data (big binary blobs, GPU-bound operators, custom user-defined functions).
Daft is meant to do this, and our redesign of distributed execution with Flotilla, enables this vision.
An Example Workload
Here's how this looks in practice with Daft:
import daft
from daft.functions.ai import embed_text
# Set daft to run distributed
daft.set_runner_ray()
df = daft.read_parquet("new_pdfs_2025_01_01")
# Download PDF bytes
df = df.with_column("pdf_bytes", df["uploaded_pdf_path"].url.download())
# Extract text
df = df.with_column(
"pages",
extract_text_from_parsed_pdf(df["pdf_bytes"])
)
# Embed text
df = df.select(
embed_text(
df["pages"],
provider="sentence_transformers",
model="Qwen/Qwen3-Embedding-0.6B"
)
)
# Write embeddings to storage
df = df.write_parquet("embedded_pdfs/")With just a few lines of declarative DataFrame code, you've defined a distributed multimodal query that:
- Ingests PDFs.
- Downloads and parses them.
- Embeds text with a GPU model.
- Writes results to storage.
So, how does all this get executed across machines in a cluster?
How Flotilla Works
At a high level, Flotilla has a similar driver / worker architecture as other distributed frameworks like Spark.
On each node in the cluster, we launch a single worker. Each worker is able to use all the resources on its node: CPU, GPU, memory, disk, and network.
Sitting above is the Flotilla scheduler on the driver. Its job is to distribute work across workers, monitor progress, and orchestrate data movement when needed. Tasks are assigned based on data locality and worker load, so computation runs close to the data while keeping cluster resources balanced.
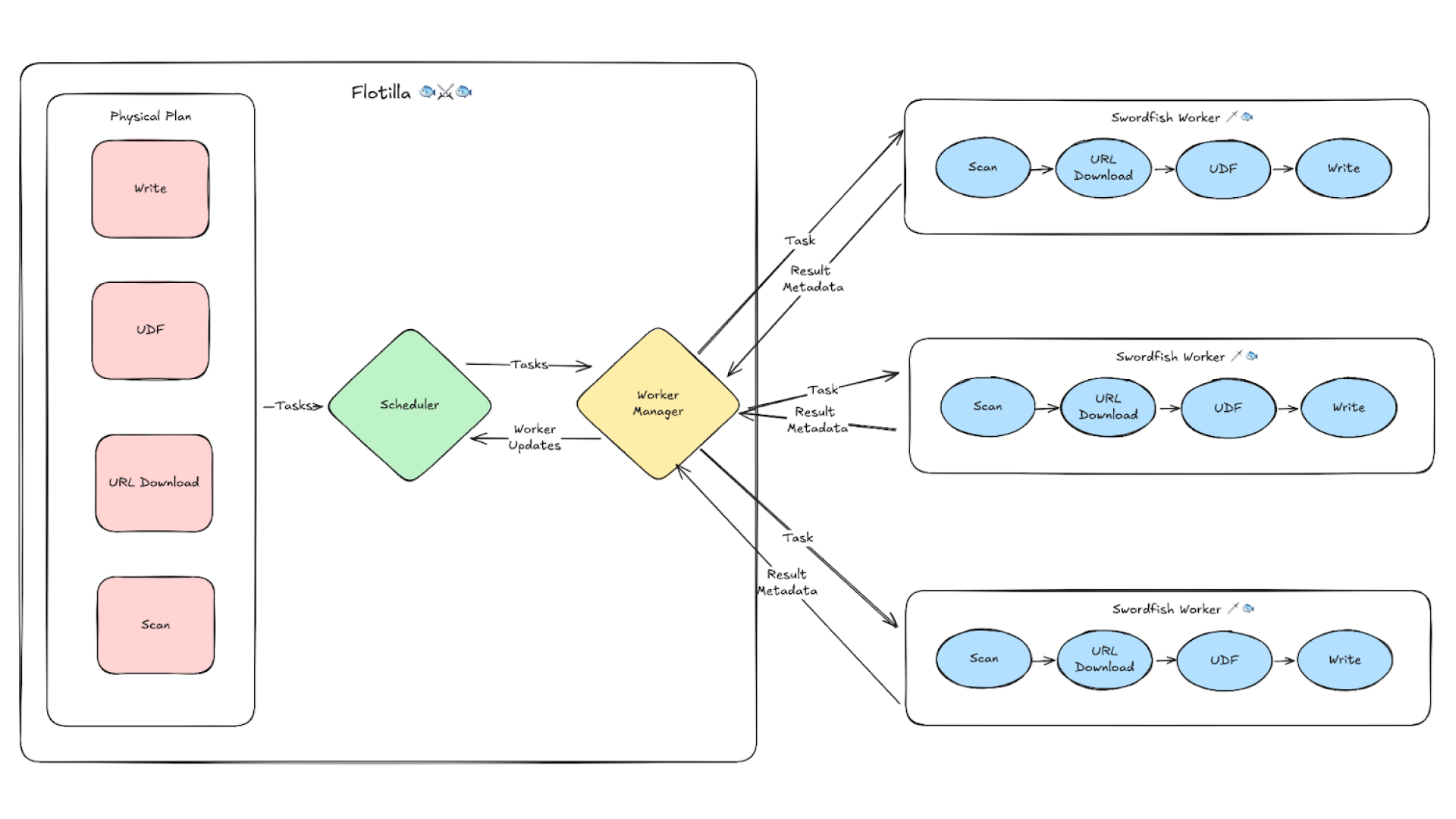
Take the earlier PDF embedding example. We still partition input files and send them across the cluster, but instead of handing each file to individual Ray workers (one per CPU core), Flotilla sends them to Swordfish workers (one per node) that's able to utilize the full resources of the machine.
Now, each worker is able to execute the pipeline in a streaming fashion across the cores of each machine, using the Swordfish engine. Swordfish processes data in small batches instead of large partitions, and executes operations concurrently instead of sequentially. This means that we don't need to wait for all 1000 PDFs to download before starting parsing or embedding. We can properly pipeline I/O with compute, keeps GPUs fed, all without blowing up memory.
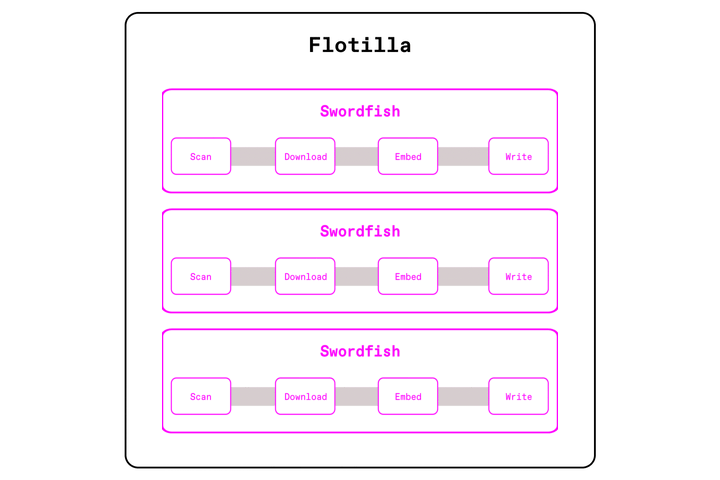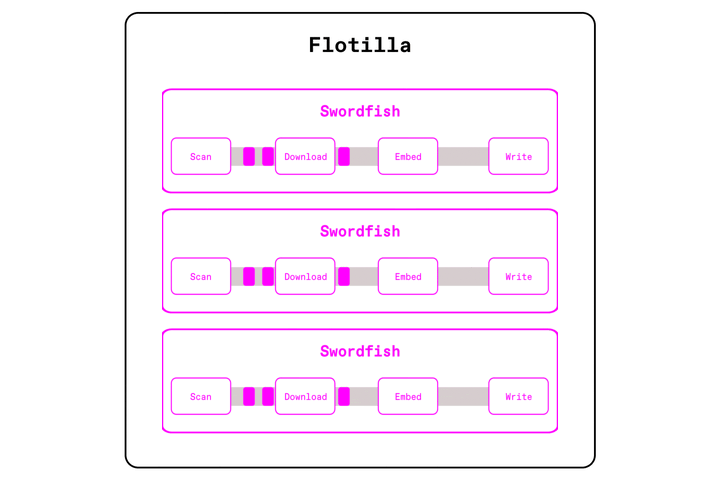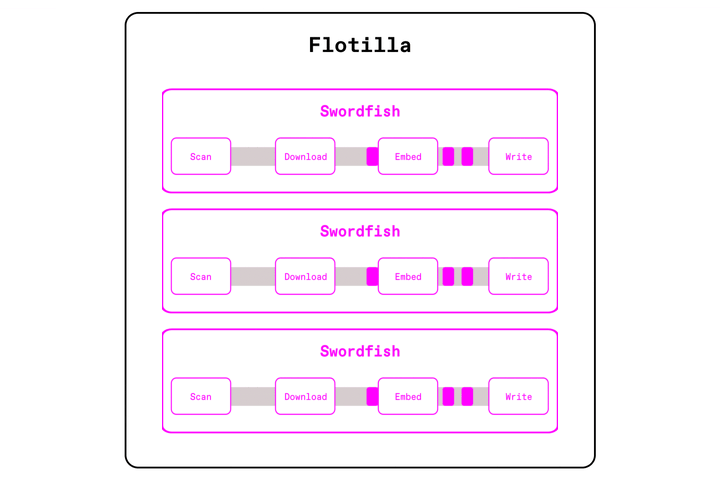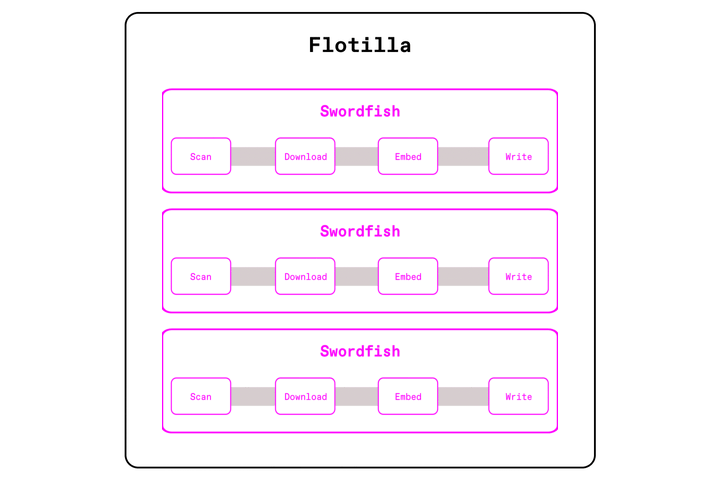
This 'swordfish per node' model achieves many benefits compared to our previous 'task per core' model:
-
Lower peak memory usage -- Data is streamed through operators instead of fully materialized between them.
-
Better resource utilization -- CPU, GPU, and network are utilized and saturated in parallel.
See our Swordfish blog for a deeper dive into how Swordfish works.
But what about operations like group-bys and joins, which require data movement across workers? Flotilla provides two shuffle mechanisms:
-
Ray Object Store Shuffle -- Ideal when data fits in memory. Fast, simple, and leverages Ray's built-in transport.
-
Flight Shuffle (Beta) -- Built on Apache Arrow Flight RPC, optimized for larger-than-memory workloads. Flight Shuffle can spill directly to disk (NVMe in particular), often faster than writing through Ray's object store. It also supports binary transfer to minimize overhead, compression to reduce disk writes, and multi-threaded parallelism.
This hybrid approach means Flotilla can scale seamlessly from gigabytes in memory to terabytes spilled across nodes -- without cluster blowups.
What Flotilla Unlocks
Flotilla isn't just a patch on the old runner, but changes what's possible when scaling multimodal pipelines. Previously, getting multimodal workloads to run reliably involved endless tunings of configs and partitions.
import daft
daft.set_execution_config(
scan_tasks_max_size_bytes=100 * 1024 * 1024,
scan_tasks_min_size_bytes=10 * 1024 * 1024,
max_sources_per_scan_task=1,
min_cpu_per_task=2,
)
df = daft.read_parquet("data")
df = df.repartition(128)But now, multimodal workloads work much better out of the box, allowing you to:
-
Run reliably at scale -- Pipelines that used to crash with OOMs now complete without retries or manual tuning.
-
Handle terabyte-scale multimodal data -- 1M+ images, PDFs, or audio files run reliably, with streaming execution that keeps memory bounded.
-
Use smaller, cheaper clusters -- Lower memory usage also means you can use machines with less memory, and are cheaper.
With Flotilla, we reduced memory usage in our entity resolution pipelines to under 15% per worker, while keeping CPU steady at 30-40%. This allows us to scale workloads that previously strained our infrastructure.
-- Garrett Weaver, ML Engineer at CloudKitchens
Benchmarks
We validated Flotilla on four real-world multimodal pipelines: audio transcription, document embedding, image classification, and video object detection. Each benchmark ran on identical AWS clusters and was also implemented in Ray Data and Spark for comparison.
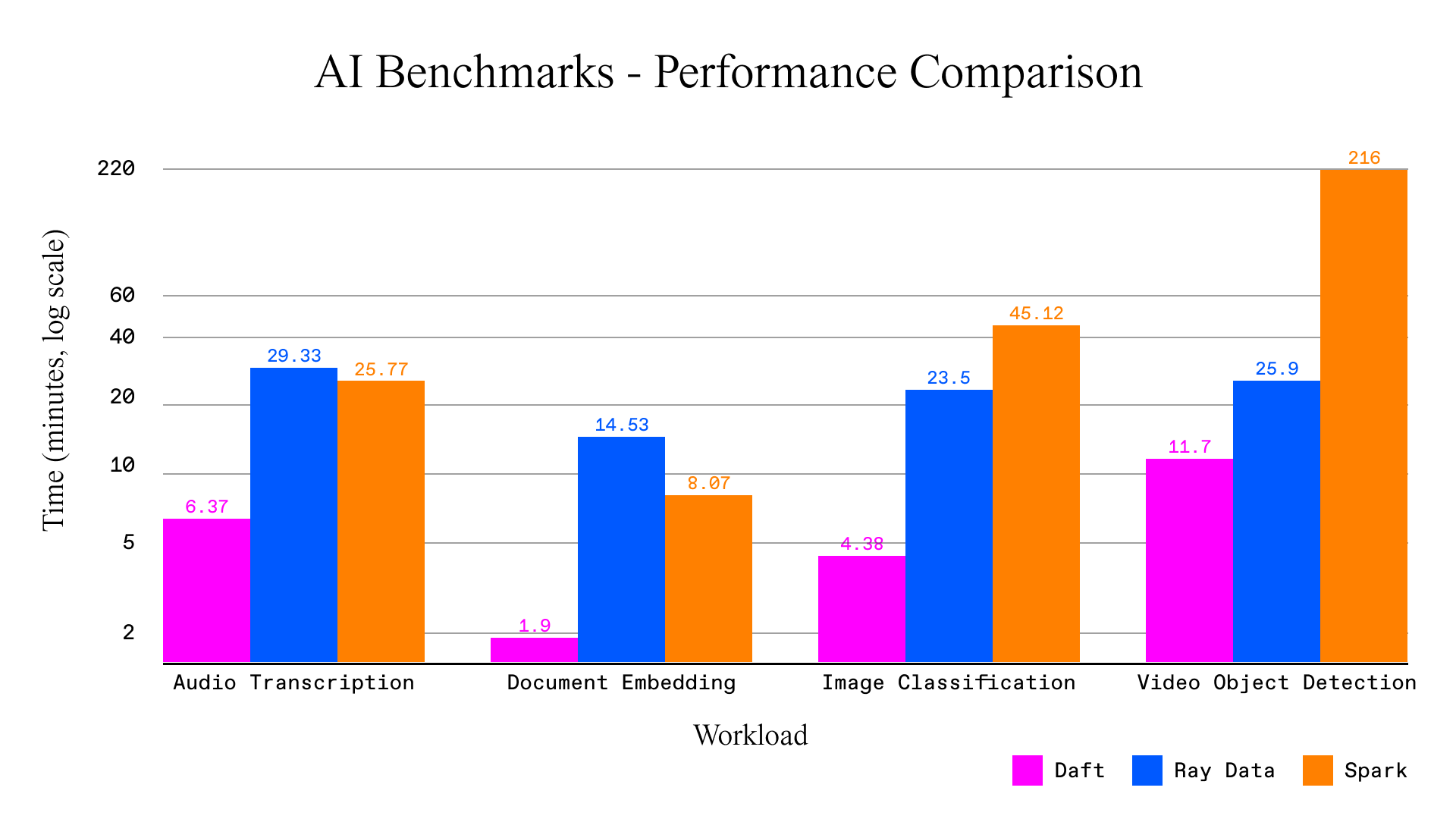
Across all workloads, Daft with Flotilla ran 2-7x faster than Ray Data and 4-18x faster than Spark, while using smaller clusters and completing without crashes.
One highlight: our video object detection pipeline finished in under 12 minutes with Flotilla, compared to over 3 hours on Spark.
We've published a benchmark blog with the full results, methodology, and code for anyone who wants to dive deeper.
Looking Ahead
Flotilla is just the beginning. Here's what's next:
-
Smarter shuffles -- Moving toward Arrow Flight as the default for large data exchanges. By spilling directly to disk and exploiting NVMe speed, Flotilla will scale well beyond memory limits.
-
Better GPU utilization -- Upcoming APIs will let Daft pipeline GPU work intelligently, reducing latency and making better use of expensive accelerators.
-
Observability -- A dedicated Daft Dashboard will expose query plans, operator stats, and cluster metrics in real time, so developers can finally understand and trust what's happening inside distributed multimodal pipelines.
Get Started
You can get started with Flotilla in just a few minutes: pip install daft
To use Flotilla, simply set the daft.set_runner_ray() command at the top of the script, or use the DAFT_RUNNER=ray environment variable.
- Explore the code and benchmarks on GitHub
- Join our Slack for support and discussion
- Sign up for early access to our managed product

