
Open-sourcing 43 Billion Tokens of SEC EDGAR
Datamule, Teraflop AI, and Eventual collaborated to release the SEC-EDGAR dataset containing 590 GB of data, spanning 8 million samples and 43 billion tokens from all major filings in the SEC EDGAR database.
by Enrico Shippole, Edited by YK Sugi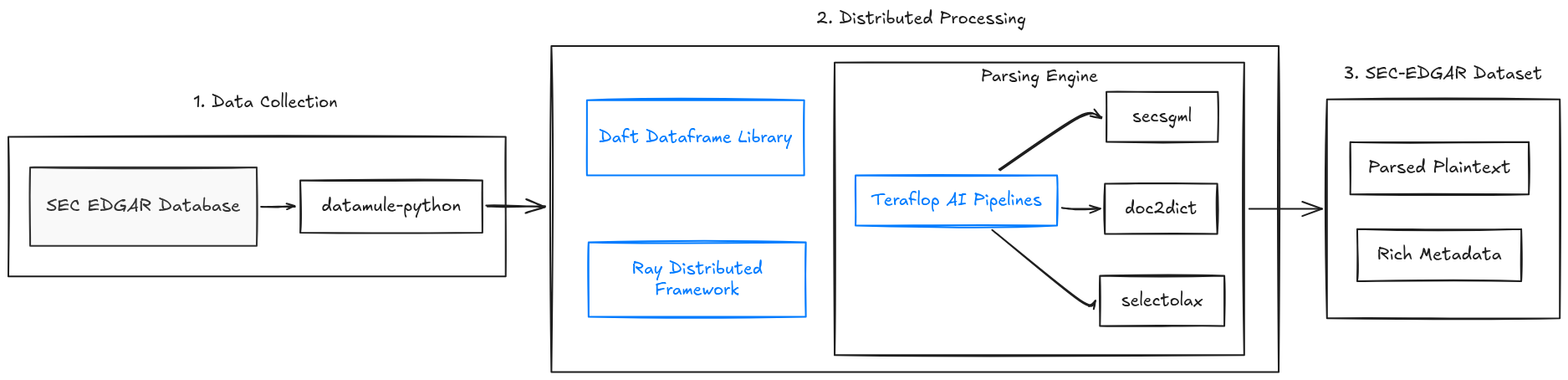
Given the increasingly closed-source nature of the U.S. AI ecosystem, it is now more important than ever to push for the proliferation of open model and dataset releases. Datamule, Teraflop AI, and Eventual collaborated to release the SEC-EDGAR dataset.
The dataset contains 590 GB of data, spanning 8 million samples and 43 billion tokens from all major filings in the SEC EDGAR database. Many different unofficial API providers charge hundreds of dollars a month to access this data with strict limits.
SEC EDGAR
The SEC's Electronic Data Gathering, Analysis, and Retrieval (EDGAR) is a free public online database providing access to millions of documents of the corporate financial filings of publicly traded companies over the last 20 years. We provide free and open access to numerous annual and quarterly reports, including filings 10-Q, 10-K, 8-5, etc., from the EDGAR system.
Datamule for collecting filings and forms
The bulk data was collected using datamule-python library and the official datamule API created by John Friedman. The datamule Python library is a package for collecting, manipulating, and processing the SEC Edgar data at scale. Datamule provides a simple open-source API interface to easily download each of a company's filings by ticker and submission type. SEC EDGAR rate limits at 10 requests per second. Constantly crawling 8 million major filings without network overhead takes over 10 days alone, following the official EDGAR guidance. The documentation for datamule can be found here.
Parsing and extraction of the SEC EDGAR data
The dataset contains the raw contents of each major filing, the extracted and parsed HTML/XML plaintext, and relevant metadata such as the filing’s accession number, filing date, period, documents, and filer. The raw document contents are provided so that you may use your own custom parser to extract the HTML/XML to plaintext. The text was parsed and extracted from the HTML/XML contents using the selectolax HTML parser and a modified version of doc2dict and secsgml libraries.
The SEC SGML library is used to parse through the Standard Generalized Markup Language document format used by the Securities and Exchange Commission and to handle daily archive and submission file types. The doc2dict library provides multiple parsers for extracting HTML, XML, and PDF content, and was used to convert to plaintext and explicitly handle table mappings. The documentation for doc2dict can be found here. We utilize @daft.cls and @daft.method.batch from Daft’s stateful UDFs to batch process the documents with doc2dict and secsgml.
Efficiently handling large strings
During the HTML/XML extraction phase of processing, an error occurred caused by the large array size of the text content in the SEC EDGAR data. Many frameworks do not support UTF-8 string arrays greater than 2GB in size. The Daft team worked promptly to provide a solution to decoding and efficiently handling these large parquet string arrays that were found throughout, allowing for the application of streamlined and minimal UDF processing.
Infrastructure and cost
Distributed processing of the data was scaled out using the highly efficient Daft dataframe library, Ray distributed framework, and Teralop AI data pipelines. The entire dataset was processed into clean plaintext form with a total of 12 cores in under 24 hours. The total cost was approximately $1.10 USD.
Plaintext and metadata
A total of 8 million individual filings were extracted with metadata. The document metadata contains the file type, sequence, filename, description, and number of SEC SGML bytes. The filer metadata contains the company name, Central Index Key, assigned Standard Industrial Classification Codes, IRS number, state of incorporation, fiscal year, act, file number, business address, and other relevant information.
Dataset availability
The dataset has been made completely, freely available on Hugging Face here. A collection of the full dataset and all individual filing subsets can be found here.
Exploratory data analysis
Below, we provide a table for the total number of crawled and released samples per document type:
| Filing | Total number of samples |
|---|---|
| Form 5 | 114,724 |
| Form 4 | 4,474,981 |
| Form 3 | 387,465 |
| S-1 | 24,866 |
| S-8 | 95,543 |
| 10-K | 223,275 |
| 8-K | 1,952,207 |
| 20-F | 19,428 |
| 10-Q | 674,240 |
| 144 | 88,726 |
| Total | 8,055,455 |
To collect the total token counts of each filing, we used the Comma v0.1 tokenizer, a BPE-based tokenizer with a vocabulary size of 64,000. The dataset encompasses a total of 43 billion clean tokens for training LLMs and building retrieval pipelines. 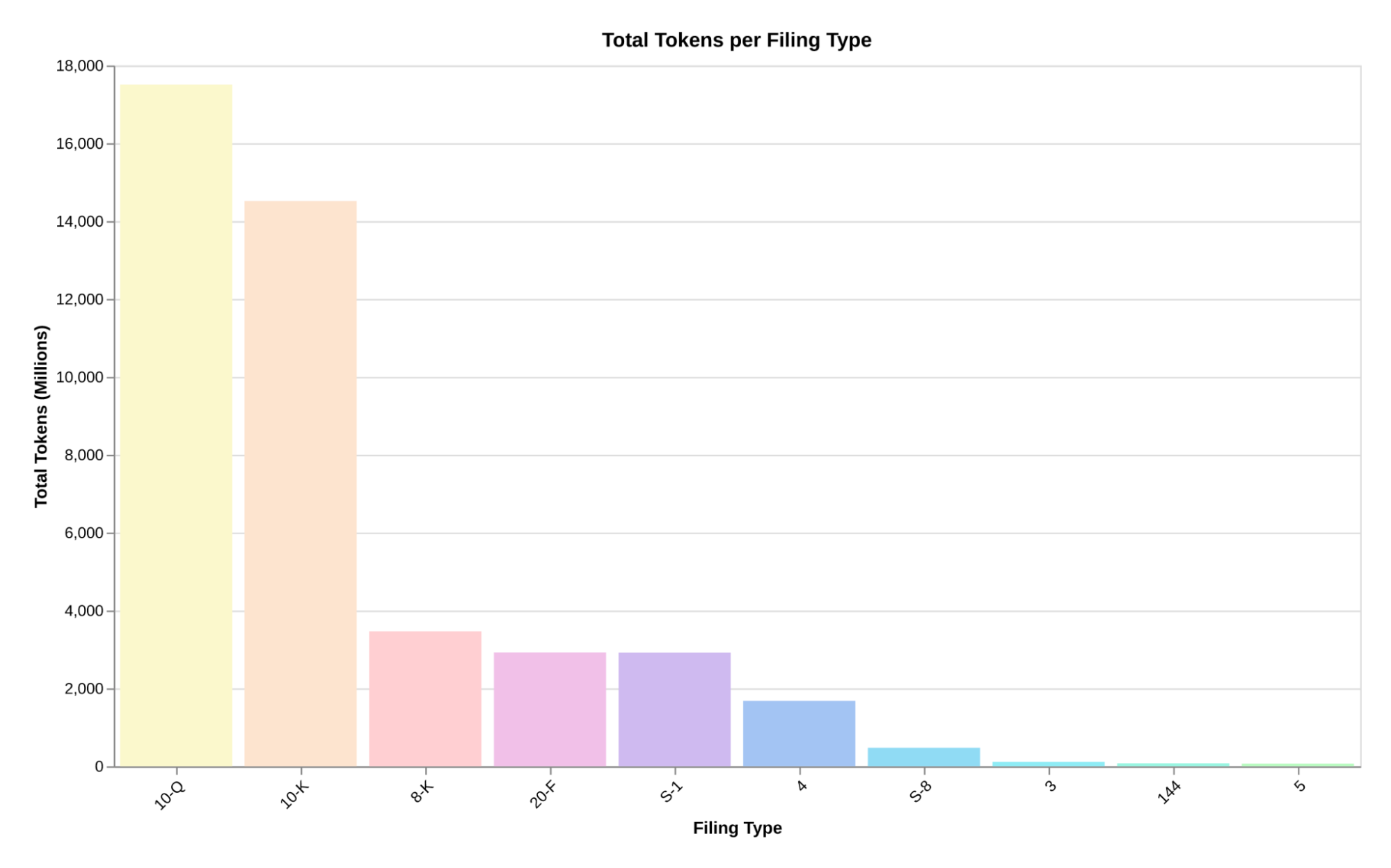
A breakdown of the total token counts for each filing is provided below:
| Filing | Total token count |
|---|---|
| 10-K | 14,518,876,137 |
| 20-F | 2,917,164,397 |
| Form 5 | 66,330,315 |
| Form 4 | 1,676,565,503 |
| Form 3 | 110,098,014 |
| 10-Q | 17,509,723,617 |
| S-1 | 2,914,107,827 |
| S-8 | 472,867,864 |
| 8-K | 3,466,866,649 |
| 144 | 73,218,304 |
| Total | 43,725,818,627 |
Next steps
The next SEC-EDGAR dataset release will include all other types of filings and forms that were not included, along with the major filings in this release. You can find a full breakdown of each document type through Datamule’s SEC Census here. The code for processing all of the data will be released in the next iteration of the Common Pile.
Acknowledgements and recognition
Thank you to our friends, Daniel van Strien and Tom Aarsen, at Hugging Face, for helping provide support and a storage grant to release this dataset to the public. This release could not have been accomplished without the generous support of datamule and John Friedman for providing access to the SEC EDGAR data and the necessary tooling for preparing the dataset. We greatly appreciate Mark Kim for taking the time to review and provide edits for this blog release.
Contact
If you would like to help support or contribute to future open-source projects and dataset releases, you can join our Discord or contact us directly here.

