
Simplifying Voice AI Analytics with Daft: Transcription, Summaries, and Embeddings at Scale
Build a Voice AI analytics pipeline with Daft and Faster-Whisper to convert raw audio into searchable transcripts, summaries, and embeddings at scale.
by Everett KlevenTLDR
This post walks through how to build a Voice AI analytics pipeline using Daft and Faster-Whisper from raw audio to searchable, multilingual transcripts. You'll learn how to:
- Transcribe long-form audio using Faster-Whisper with built-in VAD for speaker segmentation.
- Use Daft's dataframe engine to orchestrate and parallelize multimodal processing at scale.
- Generate summaries, translations, and embeddings directly from transcripts.
In short, Daft simplifies multimodal AI pipelines letting developers process, enrich, and query audio data with the same ease as tabular data.
Introducing Voice AI
Behind every AI meeting note, podcast description, and voice agent lies an AI pipeline that transcribes raw audio into text and enriches those transcripts to make it retrieval performant for downstream applications. Transcription has come a long way in the past few years. Remember when Siri used to be the state of the art? Nowadays, developers can choose from a variety speech-to-text providers like Assembly AI or Deepgram for hosted solutions, or OpenAI's Whisper and NVIDIA's Parakeet on the open-source side.
While high-quality transcription is certainly the most important stage in any voice ai workload, running speech-to-text models on raw audio isn't enough. Usually additional pipeline stages for Voice Activity Detection and Speaker Diarization are required to segment long-form recordings into neat segments.
Voice AI encompasses a broad range of tasks, but generally includes:
- Voice Activity Detection (VAD) - Detects when speech is present in an audio signal.
- Speech-to-Text (STT) - The core method of extracting transcriptions from audio.
- Speaker Diarization - Identifies and segments which speaker is talking when.
- LLM Text Generation - For summaries, translations, and more.
- Text-to-Speech (TTS) - Brings LLM responses and translations to life in spoken form.
- Turn Detection - Useful for live voice chat to help determine when a user has finished speaking and the AI should respond.
In this blog post we will focus on the first two phases, Speech-to-Text (STT) and LLM Text Generation and explore common techniques for preprocessing and enriching human speech from audio to support downstream applications like meeting Summaries, short-form editing, and embeddings.
By the end, you'll have a robust Voice AI Analytics pipeline that:
- Ingests a directory of audio files.
- Transcribes speech to text
- Generates summaries from the transcripts.
- Extracts Key Moments for Short Form Clips
- Translates transcript segments with word-level timestamps to Chinese.
- Embeds transcriptions for future use.
Traditional analytics engines have ignored multimodal data types like audio, and for good reason. Reading and processing audio data is fundamentally different from traditional columnar table workloads. At Eventual, we're making it easy to run models on multimodal data at scale with Daft. Daft is a distributed data engine optimized for multimodal AI workloads and designed to scale from your laptop to the cloud. By simplifying canonical workloads like transcription, developers can focus more on core business problems instead of low-level data processing headaches.
Challenges in Processing Audio for AI Pipelines
Audio is inherently different from traditional analytics processing. Most multimodal AI workloads require some level of preprocessing before inference, but since audio isn't stored in neat rows and columns in a table, running frontier models on audio data comes with some extra challenges.
Before we can run our STT models on audio data we'll need to read and preprocess the raw audio files into a form that the model can receive. Most machine learning models require mono-channel audio sampled at 16 KHz, usually as 1-D numpy arrays. If you are loading one hour of 48 kHz/24-bit stereo audio, memory can balloon to 518 MB of raw samples, so preprocessing is pretty much mandatory.
Reading audio files requires you to decode, buffer, and resample audio files into chunks. That means the default processing model for audio data is streaming, not batch. If you're a data engineer who has been tasked with building a new transcription pipeline, chances are you would need to venture outside your usual tooling to get the job done. From the infrastructure perspective, streaming architectures typically rely on message queues to handle back pressure and coordinate between producers and consumers. This requires a combination of systems and toolsets that need to be wired and tuned to work well together
Naturally, these levels of complexity can produce major headaches, like:
- Scaling Parallelism is only really achievable with multiprocessing or threading modules, which are error-prone (e.g., GIL limitations in CPython) and require manual process management, often resulting in race conditions or inefficient resource utilization.
- Managing Memory: Processing large quantities of audio data (e.g., WAV files at 44.1 kHz) consumes significant RAM. Developers must implement custom generators or lazy loading, but overflows are common without vigilant monitoring.
- Pipelining: Stages are hardcoded in scripts, making modifications tedious; errors in one stage (e.g., failed transcription) halt the entire process, with no automatic retry mechanisms.
- Storing and Querying Data: Outputs are saved to local files (e.g., JSON/CSV) or databases like SQLite, but querying large datasets involves custom scripts, leading to performance degradation and data inconsistency issues.
Overall, the traditional approach scales poorly, not just in compute but in development velocity as well. Now, imagine if you have to process hundreds or even thousands of hours of audio content each month. Reading a single multi-hour lossless audio file can easily peak memory into the hundreds of megabytes, which can quickly lead to OOMs. This can lead to developers facing steep debugging times, low fault tolerance, and manual orchestration.
Building a High-Performance Transcription Pipeline with Faster-Whisper
Daft has excellent support for running open-source models on data. OpenAI's Whisper has become the default model of choice for transcription for its robust speech recognition accuracy. Since releasing the model as an open-source project back in September of 2022, multiple projects like ggml-org/whisper.cpp, m-bain/WhisperX, and SYSTRAN/faster-whisper and many others have emerged to meet demand for low latency, cross-platform, high performance implementations.
Faster-Whisper comes with built-in VAD from Silero for segmenting long-form audio into neat chunks. This makes it so we don't need to worry about the length or video or handle any windowing ourselves since Whisper only operates over 30 sec chunks. We also want to take full advantage of faster-whisper's BatchedInferencePipeline to improve our throughput.
Here's the basic usage pattern:
from faster_whisper import WhisperModel, BatchedInferencePipeline
model = WhisperModel("turbo", device="cuda", compute_type="float16")
batched_model = BatchedInferencePipeline(model=model)
segments, info = batched_model.transcribe("audio.mp3", batch_size=16)
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))In order to get this work with daft, we can simply define a FasterWhisperTranscriber class and decorate it with @daft.cls(). This converts any standard Python class into a distributed massively parallel user-defined-function, enabling us take full advantage of daft's rust-backed performance.
If we focus on the __init__ method, you'll see we separate model loading from inference. Since we need to load the model from a remote repository like HuggingFace or from local storage, we only ever want to do this once. Models can easily reach multiple GB in size leading to long download times, so by initializing our model and pipeline during class instantiation, we can ensure our transcribe function can get right to work without worrying about model load times.
Shifting our focus to transcription, we can see that we input a daft.File and return a dictionary which will be materialized in our dataframe as a daft.DataType.struct(). Since faster-whisper supports reading files directly, we can use daft.File to pass file references to the transcription pipeline for simplified preprocessing. Normally, you'd need to read a numpy array with soundfile and resample the audio to 16 khz. Here we get an iterator of segments (that we will need to unpack in order to trigger inference) and some transcription metadata with info.
Finally, since we'll need the full transcript for summaries later on, we'll join the text contents of each segment object and return a dictionary of each of our results. Don't worry about the TranscriptionResult for now, that's a daft.DataType schema I generated from faster-whisper's segment and info objects.
import daft
from dataclasses import asdict
from faster_whisper import WhisperModel, BatchedInferencePipeline
from transcription_schema import TranscriptionResult
@daft.cls()
class FasterWhisperTranscriber:
def __init__(self, model="distil-large-v3", compute_type="float32", device="auto"):
self.model = WhisperModel(model, compute_type=compute_type, device=device)
self.pipe = BatchedInferencePipeline(self.model)
@daft.method(return_dtype=TranscriptionResult)
def transcribe(self, audio_file: daft.File):
"""Transcribe Audio Files with Voice Activity Detection (VAD) using Faster Whisper"""
with audio_file.to_tempfile() as tmp:
segments_iter, info = self.pipe.transcribe(
str(tmp.name),
vad_filter=True,
vad_parameters=dict(min_silence_duration_ms=500),
word_timestamps=True,
batch_size=BATCH_SIZE,
)
segments = [asdict(seg) for seg in segments_iter]
text = " ".join([seg["text"] for seg in segments])
return {"transcript": text, "segments": segments, "info": asdict(info)}Putting everything together, we can run our faster-whisper transcription pipeline on some sample data that we host on HuggingFace Datasets. You can actually just copy/paste this script into any python, and if you have uv installed, run the script with uv run faster_whiper_transcribe.py and uv will take care of all the dependencies and virtual environments in the background.
from dataclasses import asdict
import daft
from daft import col
from daft.functions import file, unnest
from faster_whisper import WhisperModel, BatchedInferencePipeline
from transcription_schema import TranscriptionResult
# Define Parameters & Constants
SOURCE_URI = "hf://datasets/Eventual-Inc/sample-files/audio/*.mp3"
SAMPLE_RATE = 16000
DTYPE = "float32"
BATCH_SIZE = 16
@daft.cls()
class FasterWhisperTranscriber:
def __init__(self, model="distil-large-v3", compute_type="float32", device="auto"):
self.model = WhisperModel(model, compute_type=compute_type, device=device)
self.pipe = BatchedInferencePipeline(self.model)
@daft.method(return_dtype=TranscriptionResult)
def transcribe(self, audio_file: daft.File):
"""Transcribe Audio Files with Voice Activity Detection (VAD) using Faster Whisper"""
with audio_file.to_tempfile() as tmp:
segments_iter, info = self.pipe.transcribe(
str(tmp.name),
vad_filter=True,
vad_parameters=dict(min_silence_duration_ms=500),
word_timestamps=True,
batch_size=BATCH_SIZE,
)
segments = [asdict(seg) for seg in segments_iter]
text = " ".join([seg["text"] for seg in segments])
return {"transcript": text, "segments": segments, "info": asdict(info)}
# Instantiate Transcription UDF
fwt = FasterWhisperTranscriber()
# Transcribe the audio files
df_transcript = (
# Discover the audio files
daft.from_glob_path(SOURCE_URI)
.limit(FILE_LIMIT)
# Wrap the path as a daft.File
.with_column("audio_file", file(col("path")))
# Transcribe the audio file with Voice Activity Detection (VAD) using Faster Whisper
.with_column("result", fwt.transcribe(col("audio_file")))
# Unpack Results
.select("path", "audio_file", unnest(col("result")))
).collect()
df_transcript.show(format="fancy", max_width=40)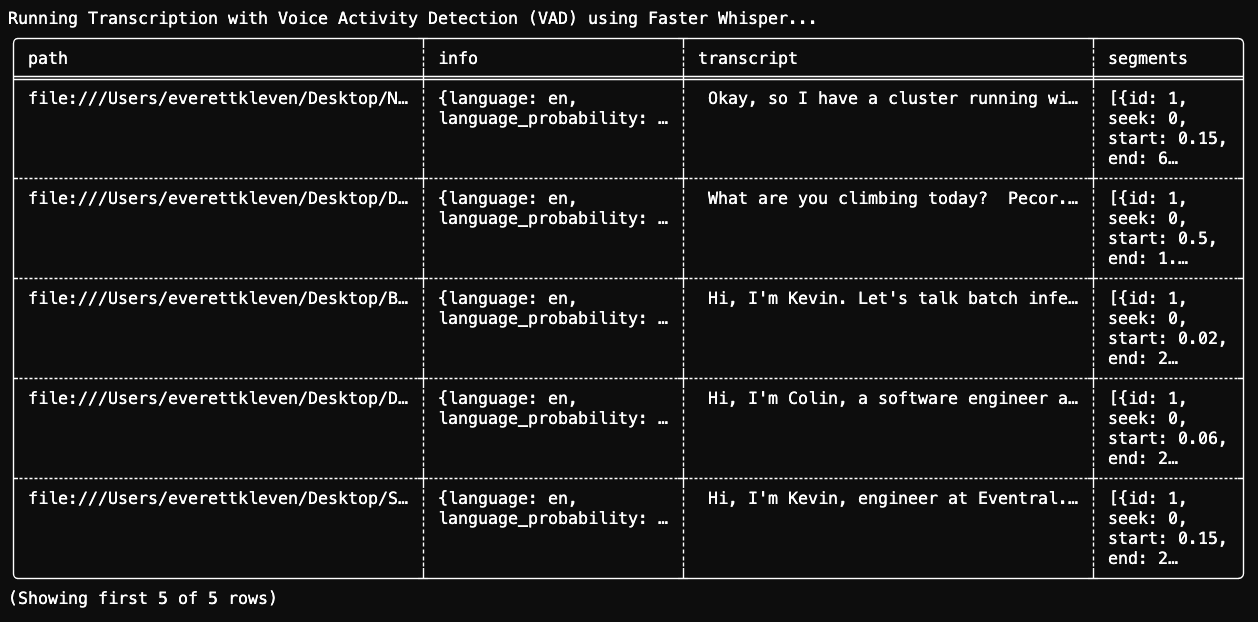
Lets break down what's happening here in the script. What we are looking at is dataframe syntax. Here we aren't manipulating variables but instead defining how a column is populated the row level. Daft's dataframe interface is useful for a number of reasons:
First, it enables developers to perform traditional tabular operations within a managed data model. That means it a lot harder to mess up your data structures since the engine takes care of it for you.
Second, defining your code at this level lets you abstract the complexity of orchestrating your processing for distributed parallelism - maximum CPU and GPU core utilization are active by default.
Third, Daft's execution engine is lazy. That means each operation we apply isn't materialized until we invoke a collection. This is because Daft runs on a push-based processing model, enabling the engine to optimize each operation by planning everything from query through the logic and finally writing to disk. Most importantly, lazy-evaluation helps the engine to decouple the transformations from the load, enabling you, the developer, to focus just on semantic operations instead of worrying if your pipeline will work for 10 GB or 10 TB.
In its early days, Daft was built to be the world's fastest distributed query engine, combining big data tech with a dataframe and sql interface that scales from laptop to cluster. Its record-setting performance on distributed S3 reads and writes is thanks to how it maximizes data throughput at the I/O level (Disk --> RAM). This breakneck performance is complimented by cloud native integrations for Apache Iceberg, Delta Lake, and Unity Catalog, which have become standard technologies within large enterprises.
Daft's memory format, built on top of Apache Arrow, gets you efficient data representation and processing, minimizing CPU and memory overhead through vectorized operations and SIMD (Single Instruction, Multiple Data) optimizations. A key strength of Apache Arrow is its standardized memory layout, which permits zero-copy data exchange across programming languages without serialization or deserialization overhead.
As Daft has matured and data processing needs have focused more on artificial intelligence, not only are companies running more inference, but the modalities of data have shifted as well. From text to multimodal, it quickly became clear that Daft is primed to simplify multimodal AI workloads.
The great thing about Daft is that extending our transcription pipeline for embeddings, summaries, or translations is just another line of code. Normally, you'd have to handle VAD, batching, and multiprocessing manually. With Daft, this complexity collapses into declarative dataframe operations.
Using LLMs for Summaries and Multilingual Outputs
Moving on to our downstream enrichment stages, summarization is a common and simple means of leveraging an LLM for publishing, socials, or search. With Daft, generating a summary from your transcripts is as simple as:
# Create an OpenAI provider, attach, and set as the default
openrouter_provider = OpenAIProvider(
name="OpenRouter",
base_url="https://openrouter.ai/api/v1",
api_key=os.environ.get("OPENROUTER_API_KEY"),
)
daft.attach_provider(openrouter_provider)
daft.set_provider("OpenRouter")
df_summaries = (
df_transcript
# Summarize the transcripts
.with_column(
"summary",
prompt(
format("Summarize the following transcript from a YouTube video belonging to {}: \n {}", daft.lit(CONTEXT), col("transcript")),
model="openai/gpt-oss-120b",
),
)
# Translate Summary for Chinese
.with_column(
"summary_chinese",
prompt(
format(
"Translate the following text to Simplified Chinese: {}",
col("summary"),
),
model="openai/gpt-oss-120b",
),
)
).collect()
print("\n\nGenerating Summaries...")
# Show the summaries and the transcript.
df_summaries.select(
"path",
"transcript",
"summary",
"summary_chinese",
).show(format="fancy", max_width=40)
In our summarization stages, it's also trivial to add translations to different languages. Since all of the data is organized and accessible, all we need to do is declare what we want and Daft takes care of the rest!
Using Segments for Localized Subtitles
Similarly, a common downstream task is preparing subtitles. Since our segments come with start and end timestamps, we can easily add another section to our Voice AI pipeline for translation as well.
# Explode the segments, embed, and translate to simplified Chinese for subtitles.
df_segments = (
df_transcript
.explode("segments")
.select(
"path",
unnest(col("segments")),
)
.with_column(
"segment_text_chinese",
prompt(
col("text"),
system_message="Translate the following text to Simplified Chinese.",
model="openai/gpt-oss-120b",
),
)
).collect()
print("\n\nGenerating Chinese Subtitles...")
# Show the segments and the transcript.
df_segments.select(
"path",
col("text"),
"segment_text_chinese",
).show(format="fancy", max_width=40)
These segments can now be used to make content more accessible for wider audiences which is a great way to increase reach.
Embedding Segments for Later Retrieval
Our final stage we will cover is embeddings. If you are going through the trouble of transcription, you might as well make that content available as a part of your knowledge base. Meeting notes might not be the most advanced AI use-case anymore, but it still provides immense value for tracking decisions and key moments in discussions.
Adding an embeddings stage is as simple as:
from daft.functions import embed_text
# Embed segment text
df_segments = (
df_segments
.with_column(
"segment_embeddings",
embed_text(
col("text"),
provider="sentence_transformers",
model="sentence-transformers/all-MiniLM-L6-v2",
),
)
).collect()
print("\n\nGenerating Embeddings for Segments...")
# Show the segments and the transcript.
df_segments.select(
"path",
"text",
"segment_embeddings",
).show(format="fancy", max_width=40)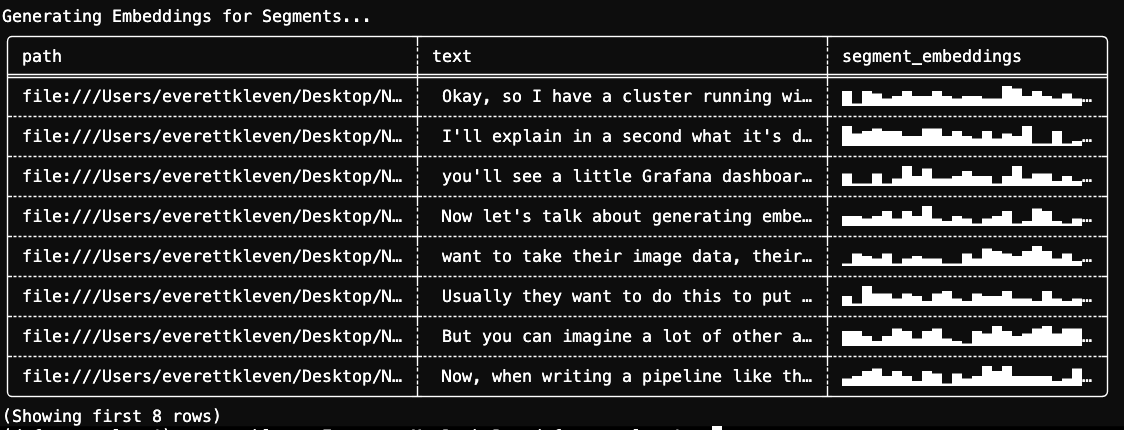
Taking a look at our results, we can see how our pipeline evolved from our podcast file paths to our transcriptions, then LLM summary/translations, and embeddings. Daft's native embedding DataType intelligently stores embedding vectors for you, regardless of their size.
Extensions and Next Steps
From here there are several directions we could take this. We could leverage the embeddings to host a Q/A chatbot that enables podcast listeners to engage with content across episodes. Questions like "What did Sam Harris say about free will in episode 267?" or "Find all discussions about AI safety across my subscribed podcasts" become trivial vector searches against our stored embeddings. We could build recommendation engines that surface hidden gems based on semantic similarity rather than just metadata tags, or create dynamic highlight reels that auto-generate shareable clips based on sentiment spikes and topic density.
The same tooling that powers each workflow also powers your analytics dashboards showcasing trending topics across the podcast universe, or supply content for automated newsletters that curate personalized episode summaries for each listener's interests. Since everything you store is queryable and performant, the only limit is your imagination.
A great next step would be to leverage Daft's cosine_distance function makes to put together a full RAG workflow for an interactive experience, but I'll let you explore that one on your own.
If you run into any issues the eventual team and growing open-source community are always active on Github and Slack. Feel free to introduce yourself or open an issue!
Conclusion
At Eventual, we're simplifying multimodal AI so you don't have to. Managing voice AI pipelines or processing thousands of hours of podcast audio ultimately comes down to a few universal needs:
- Transcripts so your content is accessible and searchable
- Summaries so your listeners can skim and find what matters
- Translations so you can localize your content to your audience
- Embeddings so people can ask questions like "Which episode talked about reinforcement learning?"
Traditionally, delivering all of this meant juggling multiple tools, data formats, and scaling headaches -- a brittle setup that doesn't grow with your workload. With Daft, you get one unified engine to process, store, and query multimodal data efficiently. The same system that ingests your audio also persists structured results in table formats ready for analytics, retrieval, or RAG workflows.
Fewer moving parts means fewer failure points, less debugging, and a much shorter path from raw audio to usable insights. For podcasters, that's more time creating great conversations. For developers, it's the multimodal AI pipeline you actually want -- fast to iterate on, easy to scale, and reliable to operate.
Next time, we'll take this pipeline a step further by using segment embeddings to extract key moments for short-form content. For now, go run some transcriptions -- and see just how easy multimodal AI can be with Daft.

