
Fall 2025 Review: OSS Updates | UDFs, Functions, & daft.File
Daft Fall 2025: AI Functions, improved UDFs, faster vLLM inference, and new daft.File VideoFile subtype - plus Bigtable sink and Common Crawl loader.
by Daft TeamIt's been an incredible month of progress for Daft. Let's take a moment to highlight all of the new features, updated capabilities, and documentation improvements that have made their way into main branch.
AI Functions and Providers
First up is the new prompt function. With daft.functions.ai.prompt the foundation has been laid for massively parallel prompt engineering, synthetic data generation, and batch tool calling. As of daft release 0.6.10 the new prompt function supports full multimodal inputs and structured outputs with the OpenAI provider via the Responses API.
import os
import daft
from daft.functions.ai import prompt
# Set Provider to OpenAI and override base_url and api_key
daft.set_provider(
"openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.environ.get("OPENROUTER_API_KEY")
)
# Create a dataframe with the quotes
df = daft.from_pydict(
{
"quote": [
"I am going to be the king of the pirates!",
"I'm going to be the next Hokage!",
],
}
)
# Use the prompt function to classify the quotes
df = df.with_column(
"response",
prompt(
messages = daft.col("quote"),
system_message="You are an anime expert. Classify the anime based on the text and returns the name, character, and quote.",
model="nvidia/nemotron-nano-9b-v2:free",
),
)
df.show(format="fancy", max_width=120)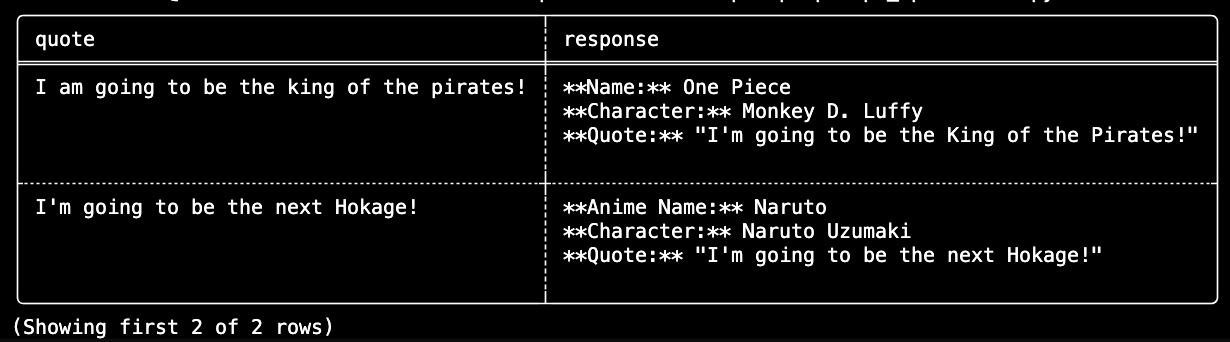
messages now supports any combination of string, image, or file expression input. This opens up a variety of use-cases from document intelligence and vision with built in integration with daft.File() and daft.DataType.image().
New experimental vLLM Provider with Dynamic Prefix Caching
Initial LLM inference functions had limited functionality and performance improvements beyond a naive UDF. The experimental VLLMPrefixCachedProvider adds async batching and prefix routing to dramatically improve large-scale LLM inference throughput. Check out the blog post to get all of the technical details on how it cuts batch inference time in half with:
- Dynamic Prefix Bucketing - improving LLM cache usage by bucketing and routing by prompt prefix.
- Streaming-Based Continuous Batching - Pipeline data processing with LLM inference to fully utilize GPUs.
Combined, these two strategies yield significant performance improvements and cost savings that scale to massive workloads. We observe that on a cluster of 128 GPUs (Nvidia L4), we are able to complete an inference workload of 200k prompts totaling 128 million tokens up to 50.7% faster.
New Stateless and Stateful UDFs have landed
When Daft's built-in functions aren't sufficient for your needs, the @daft.func and @daft.cls decorators let you run your own Python code over each row of data. Simply decorate a Python function or class, and it becomes usable in Daft DataFrame operations. New UDFs support eager execution with scalars, type-hint-driven return type inference, generators, and batch UDFs.
@daft.func: stateless row-wise UDFs (with async + generator variants and a batch variant).@daft.cls(+ optional@daft.method): stateful UDFs where you initialize once (e.g., load a model) and reuse across rows.
Should I switch now?
For most production workloads, yes. You get cleaner ergonomics, async/generators, and better typing. For more detailed info refer to the migration guide.
Stateless UDFs - @daft.func
import daft
@daft.func
def add_and_format(a: int, b: int) -> str:
return f"Sum: {a + b}"
df = daft.from_pydict({"x": [1, 2, 3], "y": [4, 5, 6]})
df = df.select(add_and_format(df["x"], df["y"]))Daft supports multiple variants to optimize for different use cases:
- Row-wise (default): Regular Python functions process one row at a time
- Async row-wise: Async Python functions process rows concurrently
- Generator: Generator functions produce multiple output rows per input row
- Batch (
@daft.func.batch): Process entire batches of data withdaft.Seriesfor high performance
Daft automatically detects which variant to use for regular functions based on your function signature. For batch functions, you must use the @daft.func.batch decorator. Another highly requested feature was adding retry semantics for transient failures, configurable with max_retries and on_error="raise".
Stateful UDFs - @daft.cls + @daft.method
import daft
@daft.cls
class TextClassifier:
def __init__(self, model_path: str):
# This expensive initialization happens once per worker
self.model = load_model(model_path)
def __call__(self, text: str) -> str:
return self.model.predict(text)
# Create an instance with initialization arguments
classifier = TextClassifier("path/to/model.pkl")
df = daft.from_pydict({"text": ["hello world", "goodbye world"]})
# Use the instance directly as a Daft function
df = df.select(classifier(df["text"]))How Stateful UDFs Work
- Lazy Initialization: When you create an instance like
classifier = TextClassifier("path/to/model.pkl"), the__init__method is not called immediately. Instead, Daft saves the initialization arguments. - Worker Initialization: During query execution, Daft calls
__init__on each instance with the saved arguments. Instances are reused for multiple rows. - Method Calls: Methods can be called with either:
- Expressions (like
df["text"]) - returns an Expression for DataFrame operations - Scalars (like
"hello") - executes immediately, initializing a local instance if needed
- Expressions (like
Similarly to daft.func, Daft supports the same variants (row-wise, async, batch, etc) for daft.method to optimize for different use cases.
daft.File Enhancements - Better File Abstraction and Media Support
One of the most powerful features for working in UDFs is the daft.File interface. The File datatype is preferable when dealing with large files that don't fit in memory or when you only need to access specific portions of a file. It provides a file-like interface with random access capabilities.
- New VideoFile Type - Introduced a new subtype for video operations with metadata and keyframe extraction.
- MIME Type Detection - Added automatic MIME detection based on extension or byte signature.
- Hugging Face Files -
hf://URI resolution for file reads from Hugging Face datasets. - Doc Fixes - Updated examples for the new immutable
daft.FileAPI.
Other Enhancements
- New daft-examples repo - With all of these new features, we've created a new dedicated repository highlighting usage patterns and pipelines from across a number of multimodal AI use-cases.
- New Common Crawl Dataset loader - Common Crawl is one of the most important open web datasets, containing more than 250 billion web pages that span 18 years of crawls. It's now easier than ever to access Common Crawl data with the
daft.datasets.common_crawl()reader. - Bigtable Sink - New capability to write
DataFrames directly to Google Cloud Bigtable, with schema-aware family mappings. - Pydantic Model Support - Automatic conversion between Pydantic models and Daft structs, improving Python-native interoperability.
Thanks for keeping up with us! As always, you can always get in touch on Github or in our Slack Community!

